

前回の記事では、JSONファイルを読み込み、CSVファイルやTSVファイルへの書き込みを
行う処理を紹介しました。
今回は、Webスクレイピング処理を紹介したいと思います。
スクレイピングとクローリング
Webスクレイピングとは、プログラムによりWeb上の情報を収集する技術になります。
プログラムの実行により、Webサイト上のページを一つずつ参照して、情報を取得していきます。
スクレイピングに似ている用語として、クローリングが有り混同しやすいので、事前に違いを
確認したいと思います。
- スクレイピング:「擦る」「かき集める」という意味を持つ “Scrape”に由来する用語で、ダウンロードしたWebページから、必要な情報を抽出する手法です。
- クローリング:「這い回る」「ハイハイする」という意味の “Crawl” に由来する用語で、Webページのハイパーリンクを辿って、次々にWebページをダウンロードする手法で、別名として「スパイダー(Spider)」や「ボット(Bot)」とも言われます。

注意事項(事前確認)
スクレイピング処理は、効率的に多くの情報を収集する事や抽出する事が出来るものの、
情報の取り扱いについては、注意が必要になります。

違法性について
Webスクレイピングの対象は、Webサイトに掲載されている情報です。
基本的には、Webサイト側が情報を公開しなければ参照できないので、人が手動で
Webサイトを検索して参照する行為と、スクレイピングによるWebサイトの検索は、
同等な行為になるので、情報の収集自体には違法性は無いと思われます。
しかし注意点として、収集した情報の取り扱い方によっては、著作権侵害による
違法行為が発生する場合があり得ます。
サイトの負荷軽減について
Webスクレイピングやクローリングは、サーバーに負荷を掛ける可能性が有ります。
Webサイトへのアクセスが不能になり、業務妨害に当たる可能性も有りますので、
取り扱いには十分に注意が必要です。
スクレイピング処理の対象となるWebサイト側で、公開用のWebAPIやRSSが提供
されていれば、そちらを利用しましょう。
利用規約について
Webサイトによっては、著作権侵害やサーバーに負荷を掛けてサービス低下が伴う可能性も有り、
利用規約にて「Webスクレイピング禁止」を記載している場合も有ります。
特に有名なサイトは、スクレイピングによるデータの不正利用やシステムへの負担を避けるため、
厳格な利用規約を設けていますので、事前に確認を頂ければと思います。
Webスクレイピングやクローリングと著作権法については、下記のサイトを参考にして下さい。

ライブラリのインストール
Webスクレイピング処理を行うには、専用ライブラリが必要になりますので、紹介します。
スクレイピング処理用 ライブラリの紹介
Webスクレイピング処理を行うPythonのライブラリは、基本的に下記の4つになります。
- BeautifulSoup:取得したWebページの情報(HTML)を解析したり、要素抽出をします。
- Requests:Webページ(静的)を取得します。
- Selenium:動的なページのスクレイピングに適しています。
- Scrapy:大量データの収集に利用します。
多くのWebページは、以下の2パターンでWebスクレイピング処理することが出来ます。
- 静的なページ:Requests + BeautifulSoup
- 動的なページ:Selenium + BeautifulSoup
Webスクレイピング処理を必要とする場合、最も多いパターンは、
- 静的なページ:Requests + BeautifulSoup
になると思いますので、上記のライブラリを利用した記事を紹介していきます。

Requestsライブラリのインストール
先ずは、Requestsライブラリをインストールします。
コマンドプロンプト または PowerShell を起動します。
インストール済みのライブラリについては、下記のコマンドで確認が出来ます。
python -m pip list
では、下記のコマンドで、Requestsライブラリをインストールしてみます。
python -m pip install requests
BeautifulSoupライブラリのインストール
次に、BeautifulSoupライブラリをインストールします。
python -m pip install beautifulsoup4
2つのライブラリ共に、インストール時にエラーが表示されませんでしたので、問題無く
インストールされていると思いますが、再度、インストール済みのライブラリを確認します。
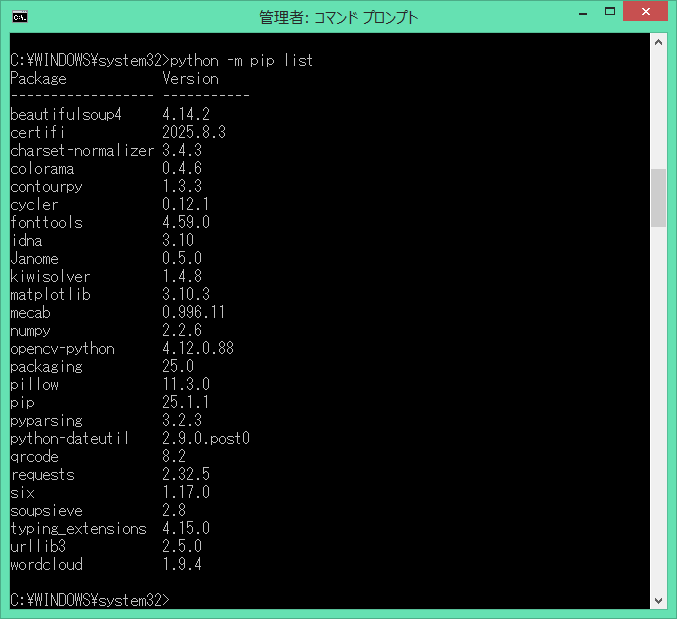
- beautifulSoup4:Version 4.14.2
- requests:Version 2.32.5
上記のライブラリがインストールされている事が、確認出来ました。
スクレイピング処理ツール
静的なページに対して、Webスクレイピング処理をするのに必要なライブラリがインストール
されましたので、実際にWebスクレイピング処理を実装して行きます。
統合開発環境(IDLE)の起動
いつものように、Python開発向けに、統合開発環境(IDLE)を起動しましょう。
IDLE Shell より、新規画面を起動します。
スクレイピング処理 ソース例:Yahoo! ニュース
それでは、Yahoo! ニュース を Webスクレイピング処理が出来るソースを紹介します。
import requests
from bs4 import BeautifulSoup
import re
from datetime import datetime as dt
line = "------------------------------------"
def get_yahoo_news():
# Yahoo! ニュースのトップページ情報を取得する
URL = "https://www.yahoo.co.jp/"
req = requests.get(URL)
# BeautifulSoupにYahoo! ニュースのページ内容を読み込ませる
soup = BeautifulSoup(req.text, "html.parser")
# Yahoo! ニュースの見出しとURLの情報を取得して出力する
data_list = soup.find_all(href=re.compile("news.yahoo.co.jp/pickup"))
i = 0
print("Yahoo! 新着ニュース情報")
print(line)
for data in data_list:
news = data.span.string
i = i + 1
print(i, ":", news)
print(line)
def header():
print(line)
def footer():
date_time = dt.now().strftime('%Y/%m/%d %H:%M:%S') + ' Now !'
print(date_time)
print(line)
if __name__ == "__main__":
header()
get_yahoo_news()
footer()
ソースの解説
import requests
from bs4 import BeautifulSoup
import re
from datetime import datetime as dtこちらは、先程、インストールした Requests、BeautifulSoup と Yahoo! ニュース を
Webスクレイピング処理する時に扱う正規表現(regex)の re環境 をインポートしています。
時間も扱うので、datetime環境もインポートしています。
# Yahoo! ニュースのトップページ情報を取得する
URL = "https://www.yahoo.co.jp/"
req = requests.get(URL)こちらでは、コメントに記載している通り、Webスクレイピング処理の対象となる
WebページのURLを指定して、Requests でYahoo! ニュース のトップページの
情報を取得しています。
# BeautifulSoupにYahoo! ニュースのページ内容を読み込ませる
soup = BeautifulSoup(req.text, "html.parser")
# Yahoo! ニュースの見出しとURLの情報を取得して出力する
data_list = soup.find_all(href=re.compile("news.yahoo.co.jp/pickup"))
こちらは、Requests で取得したWebページの情報(HTML)を BeautifulSoup に
読み込ませています。
- 第1引数には、テキスト形式のHTMLもしくはXMLを渡します。
- 第2引数には、第1引数として渡したデータを解析するために、「.parser」というメソッドを使用しています。
- HTMLを用いた場合は、「html.parser」を指定します。
- XMLを用いた場合は、「xml.parser」を指定します。
soup.find_all()メソッドを用いて、Yahoo! ニュース の ピックアップ(pickup)の解析
と要素の抽出を行っています。
具体的には、HTMLドキュメント内のhref属性に、“news.yahoo.co.jp/pickup” が
含まれる要素を抽出しています。
for data in data_list:
news = data.span.string
i = i + 1
print(i, ":", news)
こちらは、“news.yahoo.co.jp/pickup” が含まれる要素を抽出した情報から、
ループ処理を利用して、1項目毎にニュース内容を取り出しています。
“data.span.string” で、<span>タグの内容を文字列として取得しています。
ヘッダー:header() 処理 と フッター:footer() 処理は、IDLE Shell(コンソール)に、
”横線” と “処理した時間” を出力する処理と簡単なので、説明は省略します。
スクレイピング処理ソースの実行例
実際に、ソースを起動して、Webスクレイピング処理 を実行してみましょう。
作成したソースの上部のタブメニューより、Run → Run Module を選択するか、
F5キーを押下して、ソースを実行します。

ソースを起動して、エラーが無ければ、IDLE Shell には、Yahoo News より
Webスクレイピング処理した新着ニュース情報が表示されます。

実際に、Yahoo! ニュース(Webページ)と比べてみましょう。

主要タブで表示されているニュースタイトル(8項目)は、Webスクレイピング処理した
新着ニュース情報と内容が同じで有ると、確認が出来ると思います。
7項目に大谷翔平選手の記事が表示されていますので、この記事の付近の Webサイトで
ソースも確認してみます。
Webサイト上でマウスを右クリックして、ページのソースを表示 を選択するか、
Ctrl + U を押下して頂ければ、Webサイトのソースが表示されます。
news.yahoo.co.jp/pickup
上記の内容でWebサイト内を検索して頂いて、7項目には、大谷翔平選手の記事が
<span></span>タグ内で確認出来ると思います。

まとめ
今回は、Webスクレイピング処理を紹介しました。
要点は、下記の通りとなります。
- 注意事項(著作権侵害、サーバー負荷、利用規約)
- スクレイピングとクローリング
- Requests + BeautifulSoup
- ライブラリのインストール
- Yahoo! ニュースのWebスクレイピング処理
今回で、Webスクレイピング処理が出来るようになりましたので、次回は、WordCloud生成と
組み合わせた処理を行う記事を紹介しようと思います。


- イラスト:いらすとや より引用


コメント