

前回の記事では、便利なツールとして、Pythonで、WordCloudの生成ツールを紹介しました。
今回は、前回のWordCloudの生成ツールでも登場した形態素解析について、
もう少し深堀りして紹介します。
先ずは、前回のWordCloudの記事でも紹介しました形態素解析について、振り返ります。
形態素解析(分かち書き)
WordCloudの実装する際に、前提処理を行うのが、形態素解析になります。
形態素解析は、自然言語のテキストデータをいくつかの単位に分け、各単語の品詞や活用などを
解析・判別して取り出す処理です。
形態素は、言語で意味を持つ最小単位にする事です。
テキストを形態素に分割する処理は、分かち書き(tokenization)とも呼ばれており、
こちらの方が、聞き覚えの有る方もいると思います。
形態素解析器(ソフト/エンジン)
形態素解析は、実際に形態素解析器(ソフト/エンジン)を利用して、各単語の品詞や
活用などを解析・判別して取り出します。
日本語の形態素解析器(ソフト/エンジン)として、有名なのは下記になります。
- ChaSen(茶筌):2012年に奈良先端科学技術大学院大学松本研究室で開発
- JUMAN:2014年に京都大学黒橋・褚・村脇研究室で開発
- KAKASI(かかし):Namazu等の全文検索エンジンと組み合わせで用いられる
- KyTea(キューティー):京都テキスト解析ツールキット
- MeCab(和布蕪):Google 日本語入力開発者の一人である工藤拓氏によって開発
- Janome(蛇の目):Python用の形態素解析エンジン
- Kagome(籠目):Go用の形態素解析エンジン
辞書 (dictionary)
品詞や活用形の特定は、辞書 (dictionary) を活用して行うのが一般的です。
日本語の形態素解析用の辞書として、有名なのは下記になります。
- ipadic:ChaSen用の辞書 → IPA 品詞体系をもとに設計
- UniDic:MeCab用の辞書
- NAIST-jdic:ChaSen、MeCab用の辞書
- JUMAN用の辞書 → 益岡・田窪文法をもとに設計
形態素解析の詳細については、下記を参照して下さい。

WordCloud処理
形態素解析器と、WordCloudの処理の順番と役割を簡単に紹介します。
- 形態素解析器:各単語の品詞や活用などを解析・判別して抽出
- WordCloud:単語ごとに出現頻度をカウントします
- WordCloud:出現頻度に応じて、サイズを変更して単語を描画します
では、形態素解析について、もう少し深堀りしてみます。
品詞一覧
MeCabで利用される品詞一覧は、pos-id.def というファイルの中に入っています。
MeCabをインストールしたパソコン環境にも寄りますが、MeCabを直接ダウンロードして
インストールした場合の例は、下記になります。
c:/Program Files/MeCab/dic/ipadic/pos-id.def
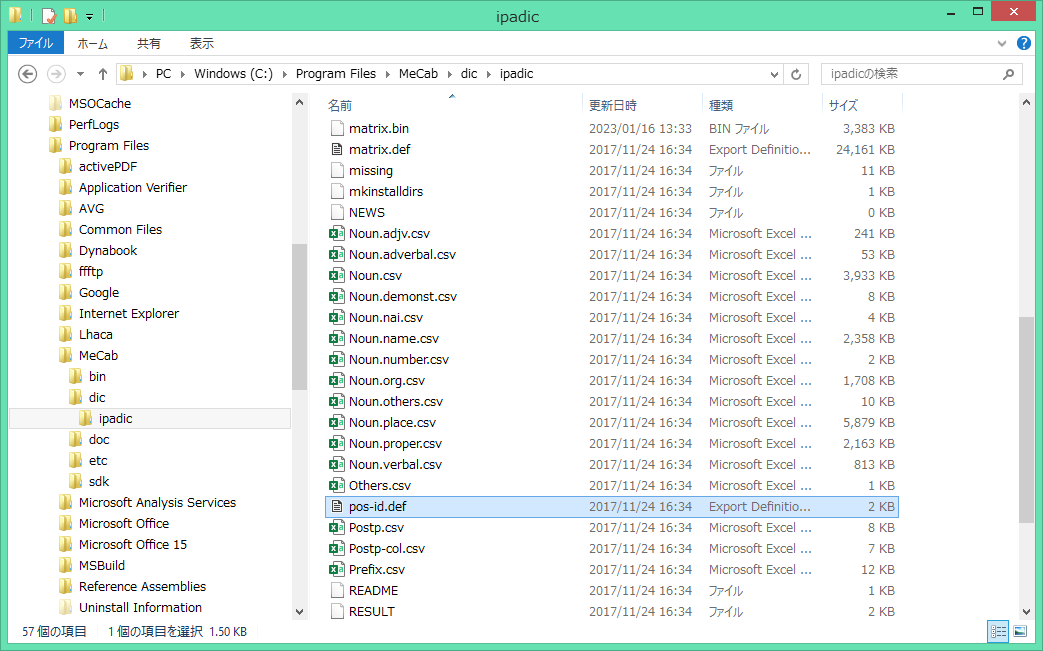
pos-id.def には、全部で69品詞(品詞ID:0~68)が入っています。
内容は、下記のように品詞名と品詞細分類1~3、品詞IDの順で並んでいます。
その他,間投,*,* 0 フィラー,*,*,* 1 感動詞,*,*,* 2 記号,アルファベット,*,* 3 記号,一般,*,* 4 記号,括弧開,*,* 5 記号,括弧閉,*,* 6 記号,句点,*,* 7 記号,空白,*,* 8 記号,読点,*,* 9 形容詞,自立,*,* 10 形容詞,接尾,*,* 11 形容詞,非自立,*,* 12 助詞,格助詞,一般,* 13 助詞,格助詞,引用,* 14 助詞,格助詞,連語,* 15 助詞,係助詞,*,* 16 助詞,終助詞,*,* 17 助詞,接続助詞,*,* 18 助詞,特殊,*,* 19 助詞,副詞化,*,* 20 助詞,副助詞,*,* 21 助詞,副助詞/並立助詞/終助詞,*,* 22 助詞,並立助詞,*,* 23 助詞,連体化,*,* 24 助動詞,*,*,* 25 接続詞,*,*,* 26 接頭詞,形容詞接続,*,* 27 接頭詞,数接続,*,* 28 接頭詞,動詞接続,*,* 29 接頭詞,名詞接続,*,* 30 動詞,自立,*,* 31 動詞,接尾,*,* 32 動詞,非自立,*,* 33 副詞,一般,*,* 34 副詞,助詞類接続,*,* 35 名詞,サ変接続,*,* 36 名詞,ナイ形容詞語幹,*,* 37 名詞,一般,*,* 38 名詞,引用文字列,*,* 39 名詞,形容動詞語幹,*,* 40 名詞,固有名詞,一般,* 41 名詞,固有名詞,人名,一般 42 名詞,固有名詞,人名,姓 43 名詞,固有名詞,人名,名 44 名詞,固有名詞,組織,* 45 名詞,固有名詞,地域,一般 46 名詞,固有名詞,地域,国 47 名詞,数,*,* 48 名詞,接続詞的,*,* 49 名詞,接尾,サ変接続,* 50 名詞,接尾,一般,* 51 名詞,接尾,形容動詞語幹,* 52 名詞,接尾,助数詞,* 53 名詞,接尾,助動詞語幹,* 54 名詞,接尾,人名,* 55 名詞,接尾,地域,* 56 名詞,接尾,特殊,* 57 名詞,接尾,副詞可能,* 58 名詞,代名詞,一般,* 59 名詞,代名詞,縮約,* 60 名詞,動詞非自立的,*,* 61 名詞,特殊,助動詞語幹,* 62 名詞,非自立,一般,* 63 名詞,非自立,形容動詞語幹,* 64 名詞,非自立,助動詞語幹,* 65 名詞,非自立,副詞可能,* 66 名詞,副詞可能,*,* 67 連体詞,*,*,* 68
出力フォーマット
また、下記のような出力フォーマットは、dicrc というファイルの中に入っています。
c:/Program Files/MeCab/dic/ipadic/dicrc
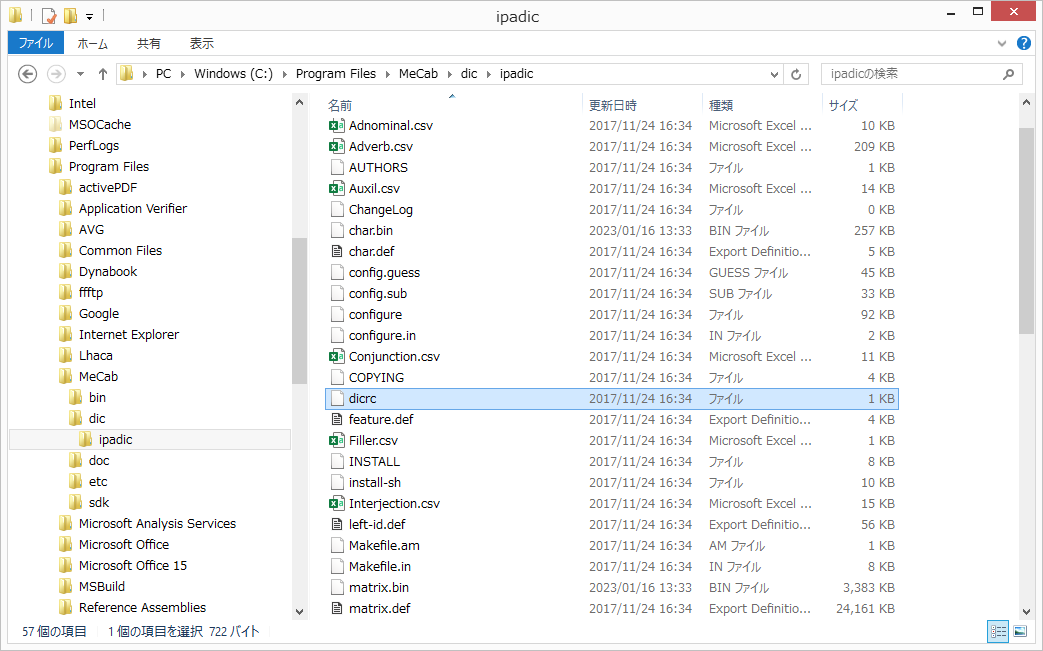
内容は、下記のようになっています。
; ; Configuration file of IPADIC ; ; $Id: dicrc,v 1.4 2006/04/08 06:41:36 taku-ku Exp $; ; cost-factor = 800 bos-feature = BOS/EOS,*,*,*,*,*,*,*,* eval-size = 8 unk-eval-size = 4 config-charset = EUC-JP ; yomi node-format-yomi = %pS%f[7] unk-format-yomi = %M eos-format-yomi = \n ; simple node-format-simple = %m\t%F-[0,1,2,3]\n eos-format-simple = EOS\n ; ChaSen node-format-chasen = %m\t%f[7]\t%f[6]\t%F-[0,1,2,3]\t%f[4]\t%f[5]\n unk-format-chasen = %m\t%m\t%m\t%F-[0,1,2,3]\t\t\n eos-format-chasen = EOS\n ; ChaSen (include spaces) node-format-chasen2 = %M\t%f[7]\t%f[6]\t%F-[0,1,2,3]\t%f[4]\t%f[5]\n unk-format-chasen2 = %M\t%m\t%m\t%F-[0,1,2,3]\t\t\n eos-format-chasen2 = EOS\n
MeCabの出力フォーマットの日本語表現については、下記となっています。

MeCabの解析処理
実際に紹介した品詞一覧と出力フォーマットを利用して、形態素解析器(Mecab)の処理をして、
解析結果を可視化してみます。
統合開発環境(IDLE)の起動
いつものように、Python開発向けに、統合開発環境(IDLE)を起動しましょう。
IDLE Shell より、新規画面を起動します。
MeCab 解析のソース例
それでは、MeCab を利用した解析ソースを紹介します。
# ライブラリのインポート
import MeCab
from datetime import datetime as dt
import time
outfile = 'C:/work/python/data/Input_MeCab_Analysis.txt'
def MeCab_Analysis(msg):
# 開始時間
start_time = time.time()
tdatetime = dt.now()
string_start_time = "処理開始日時:"+tdatetime.strftime('%Y/%m/%d %H:%M:%S')
print(string_start_time)
with open(outfile, 'a', encoding='utf-8') as f: # w:write a:add
f.write(string_start_time +'\n')
f.write("Enter a message = "+msg +'\n')
# テキストの読み込み
text = msg
# 単語の分割
# オプション:辞書は形態素解析器ChaSen用の辞書を採用
tagger = MeCab.Tagger ("-Ochasen")
# 形態素解析
node = tagger.parseToNode(text)
while node is not None:
string_asterisk = '****************************'
string_node_surface = '[表層形]:' + str(node.surface)
string_node_feature_0 = '[品詞] 0:' + node.feature.split(",")[0]
string_node_feature_1 = '[品詞細分類1] 1:' + node.feature.split(",")[1]
string_node_feature_2 = '[品詞細分類2] 2:' + node.feature.split(",")[2]
string_node_feature_3 = '[品詞細分類3] 3:' + node.feature.split(",")[3]
string_node_feature_4 = '[活用型] 4:' + node.feature.split(",")[4]
string_node_feature_5 = '[活用形] 5:' + node.feature.split(",")[5]
string_node_feature_6 = '[原形] 6:' + node.feature.split(",")[6]
string_node_feature_7 = '[読み] 7:' + node.feature.split(",")[7]
string_node_feature_8 = '[発音] 8:' + node.feature.split(",")[8]
# ファイル書き込み
with open(outfile, 'a', encoding='utf-8') as f: # w:write a:add
f.write(string_asterisk +'\n')
f.write(string_node_surface +'\n')
f.write(string_node_feature_0 +'\n')
f.write(string_node_feature_1 +'\n')
f.write(string_node_feature_2 +'\n')
f.write(string_node_feature_3 +'\n')
f.write(string_node_feature_4 +'\n')
f.write(string_node_feature_5 +'\n')
f.write(string_node_feature_6 +'\n')
f.write(string_node_feature_7 +'\n')
f.write(string_node_feature_8 +'\n')
# コンソール出力
print(string_asterisk)
print(string_node_surface)
print(string_node_feature_0)
print(string_node_feature_1)
print(string_node_feature_2)
print(string_node_feature_3)
print(string_node_feature_4)
print(string_node_feature_5)
print(string_node_feature_6)
print(string_node_feature_7)
print(string_node_feature_8)
node = node.next # 書き忘れると無限ループになるので注意
# 終了時間
end_time = time.time()
# 差分
dif_time = end_time - start_time
# 終了時間
tdatetime = dt.now()
string_line = "----------------------------------"
string_end_time = "処理終了日時:"+ tdatetime.strftime('%Y/%m/%d %H:%M:%S')
string_dif_time = "処理時間:"+ str(dif_time) +"秒"
string_success = "Input Data MeCab Analysis Successfully"
with open(outfile, 'a', encoding='utf-8') as f: # w:write a:add
f.write(string_line +'\n')
f.write(string_end_time +'\n')
f.write(string_line +'\n')
f.write(string_dif_time +'\n')
f.write(string_line +'\n')
f.write(string_success +'\n')
# コンソール出力
print(string_line)
print(string_end_time)
print(string_line)
print(string_dif_time)
print(string_line)
print(string_success)
print(string_line)
if __name__ == "__main__":
try:
while True:
msg = input("Enter a message = ")
msg_leng = len(msg)
print('msg_leng : ', msg_leng)
print('---------------------------')
MeCab_Analysis(msg)
except Exception as e:
print("Exception : ", e)
finally:
print("MeCab Analysis End...")
ソースの解説
import MeCab
from datetime import datetime as dt
import time
outfile = 'C:/work/python/data/Input_MeCab_Analysis.txt'
こちらはの先頭文では、MeCab と日時処理を行うライブラリ環境をインポートしています。
また、outfiile として、解析した結果をテキストファイルで保存する場所とファイル名を
指定しています。
保存場所とファイル名については、お手持ちのパソコン環境に合わせて、修正して下さい。
start_time = time.time()
tdatetime = dt.now()
string_start_time = "処理開始日時:"+tdatetime.strftime('%Y/%m/%d %H:%M:%S')
print(string_start_time)
with open(outfile, 'a', encoding='utf-8') as f: # w:write a:add
f.write(string_start_time +'\n')
f.write("Enter a message = "+msg +'\n')
こちらは、処理開始日時を、IDLE Shell と テキストファイル に出力しています。
テキストファイル には、見やすくする為、改行コード(’\n’)を入れています。
テキストファイル の書き込み方法は、‘a’ の addモード(追記)を利用しています。
纏まったテキスト文を一度に書き込む場合は、‘w’ の writeモード(上書き)を利用する事も
有ると思いますが、今回の解析処理では、複数の単語ごとに解析結果を表示するので、
‘a’ の addモード(追記)を利用しています。
‘a’ のみより、mode = ‘a’ の方が、丁寧な記載になります。
# テキストの読み込み
text = msg
# 単語の分割
# オプション:辞書は形態素解析器ChaSen用の辞書を採用
tagger = MeCab.Tagger ("-Ochasen")
# 形態素解析
node = tagger.parseToNode(text)
こちらでは、WordCloudの処理同様、MeCab の Taggerメソッドを利用して、
辞書を指定しています。
“Chasen” という方法で、入力されたテキスト文を単語に分けて出力の設定をしています。
while node is not None:
string_asterisk = '****************************'
string_node_surface = '[表層形]:' + str(node.surface)
string_node_feature_0 = '[品詞] 0:' + node.feature.split(",")[0]
string_node_feature_1 = '[品詞細分類1] 1:' + node.feature.split(",")[1]
string_node_feature_2 = '[品詞細分類2] 2:' + node.feature.split(",")[2]
string_node_feature_3 = '[品詞細分類3] 3:' + node.feature.split(",")[3]
string_node_feature_4 = '[活用型] 4:' + node.feature.split(",")[4]
string_node_feature_5 = '[活用形] 5:' + node.feature.split(",")[5]
string_node_feature_6 = '[原形] 6:' + node.feature.split(",")[6]
string_node_feature_7 = '[読み] 7:' + node.feature.split(",")[7]
string_node_feature_8 = '[発音] 8:' + node.feature.split(",")[8]
こちらは、入力されたテキスト文を、MeCab で解析した結果、一旦、出力フォーマット毎に
ワークデータへ代入しています。
with open(outfile, 'a', encoding='utf-8') as f: # w:write a:add
f.write(string_asterisk +'\n')
f.write(string_node_surface +'\n')
f.write(string_node_feature_0 +'\n')
f.write(string_node_feature_1 +'\n')
f.write(string_node_feature_2 +'\n')
f.write(string_node_feature_3 +'\n')
f.write(string_node_feature_4 +'\n')
f.write(string_node_feature_5 +'\n')
f.write(string_node_feature_6 +'\n')
f.write(string_node_feature_7 +'\n')
f.write(string_node_feature_8 +'\n')
print(string_asterisk)
print(string_node_surface)
print(string_node_feature_0)
print(string_node_feature_1)
print(string_node_feature_2)
print(string_node_feature_3)
print(string_node_feature_4)
print(string_node_feature_5)
print(string_node_feature_6)
print(string_node_feature_7)
print(string_node_feature_8)
node = node.next
こちらは、MeCab で解析した結果が代入されたワークデータを、テキストファイル(保存) と
IDLE Shell 上に出力しています。
テキストファイル には、見やすくする為、改行コード(’\n’)を入れています。
end_time = time.time()
dif_time = end_time - start_time
tdatetime = dt.now()
string_line = "----------------------------------"
string_end_time = "処理終了日時:"+ tdatetime.strftime('%Y/%m/%d %H:%M:%S')
string_dif_time = "処理時間:"+ str(dif_time) +"秒"
string_success = "Input Data MeCab Analysis Successfully"
with open(outfile, 'a', encoding='utf-8') as f: # w:write a:add
f.write(string_line +'\n')
f.write(string_end_time +'\n')
f.write(string_line +'\n')
f.write(string_dif_time +'\n')
f.write(string_line +'\n')
f.write(string_success +'\n')
print(string_line)
print(string_end_time)
print(string_line)
print(string_dif_time)
print(string_line)
print(string_success)
print(string_line)
こちらは、処理終了日時と処理時間を、IDLE Shell と テキストファイル に出力しています。
テキストファイル には、見やすくする為、改行コード(’\n’)を入れています。
if __name__ == "__main__":
try:
while True:
msg = input("Enter a message = ")
msg_leng = len(msg)
print('msg_leng : ', msg_leng)
print('---------------------------')
MeCab_Analysis(msg)
except Exception as e:
print("Exception : ", e)
finally:
print("MeCab Analysis End...")
こちらは、IDLE Shell で、テキスト文が入力されたら、テキスト文の長さを表示した後、
形態素解析器(MeCab)の解析を行う関数:MeCab_Analysis()を呼び出しています。
また、エラーハンドリングと最終処理を記載しています。
MeCab解析ソースの実行例
実際に、ソースを起動して解析してみましょう。
作成したソース画面の上部のタブメニューより、Run → Run Module を選択して、
ソースを起動します。
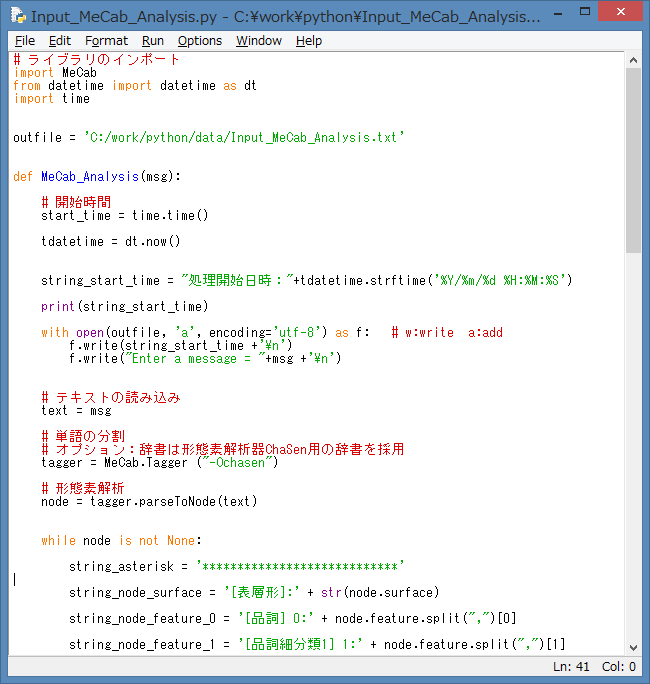
ツールを動かして、エラーが無ければ、IDLE Shell には、テキスト文の入力を促すメッセージが
表示されますので、形態素解析器(MeCab)で解析したいテキスト文を入力します。
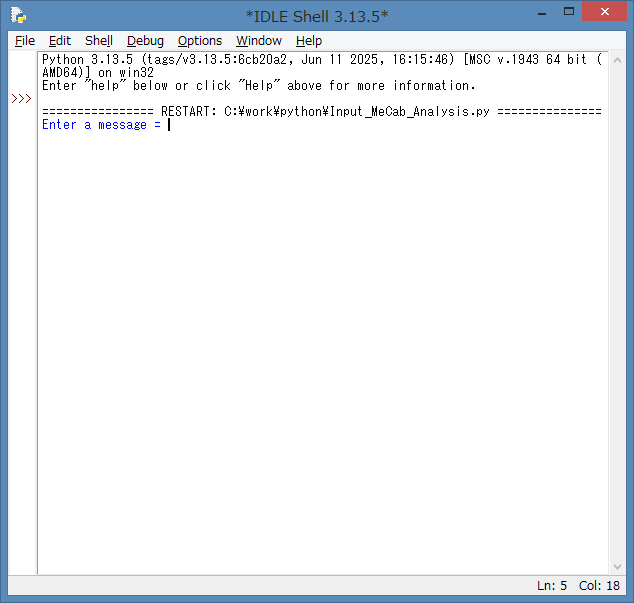
今回は、下記の記事を例として、
エアコンのブランド「霧ヶ峰」。もちろん、長野県諏訪市の「霧ケ峰高原」が由来となっています。
を入力してみます。
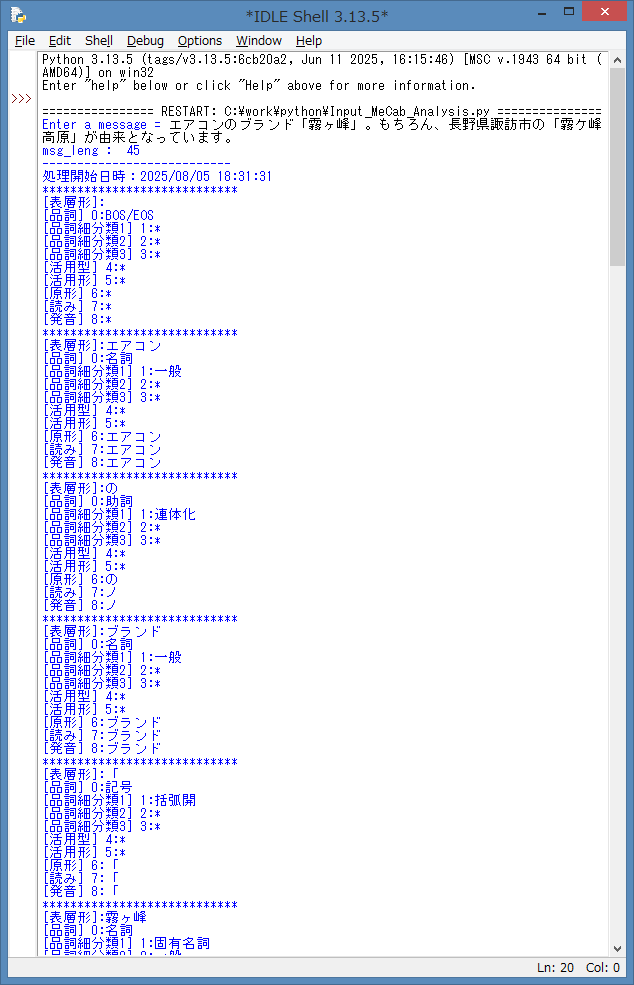
エアコン の ブランド 「 霧ヶ峰 ・・・と、入力されたテキスト文から、それぞれ単語に
分けられて、下記の出力フォーマットで解析されている事が分かりますね。
IDLE Shell を、最終行まで下にスクロールしてみます。
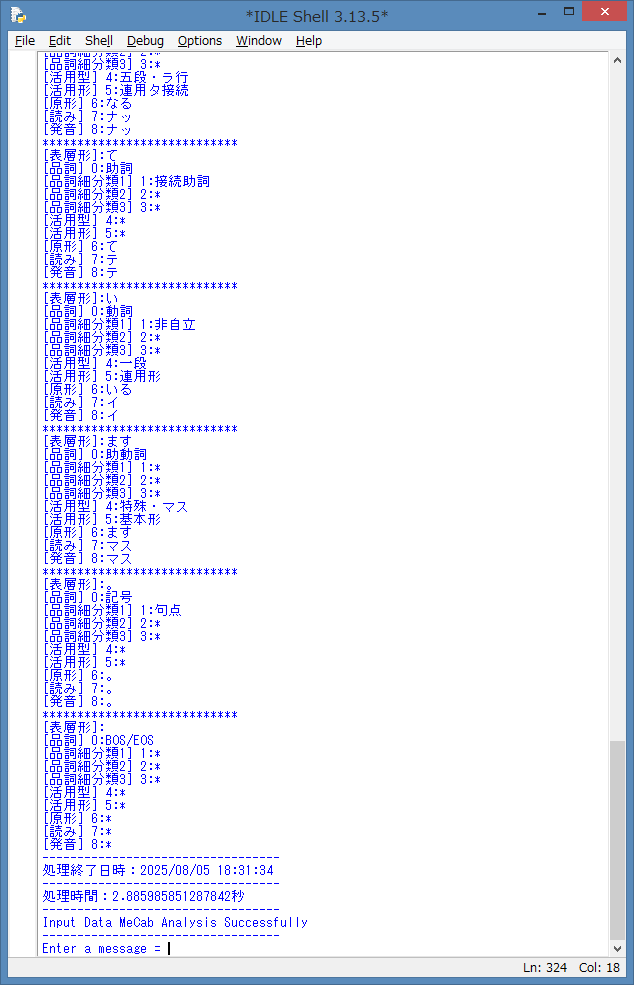
入力されたテキスト文の解析が終了し、処理終了日時と処理時間が表示されているのを
確認する事が出来ました。
では、保存したテキストファイルの内容も確認してみます。
上記の Input_MeCab_Analysis.txt を、開いてみます。
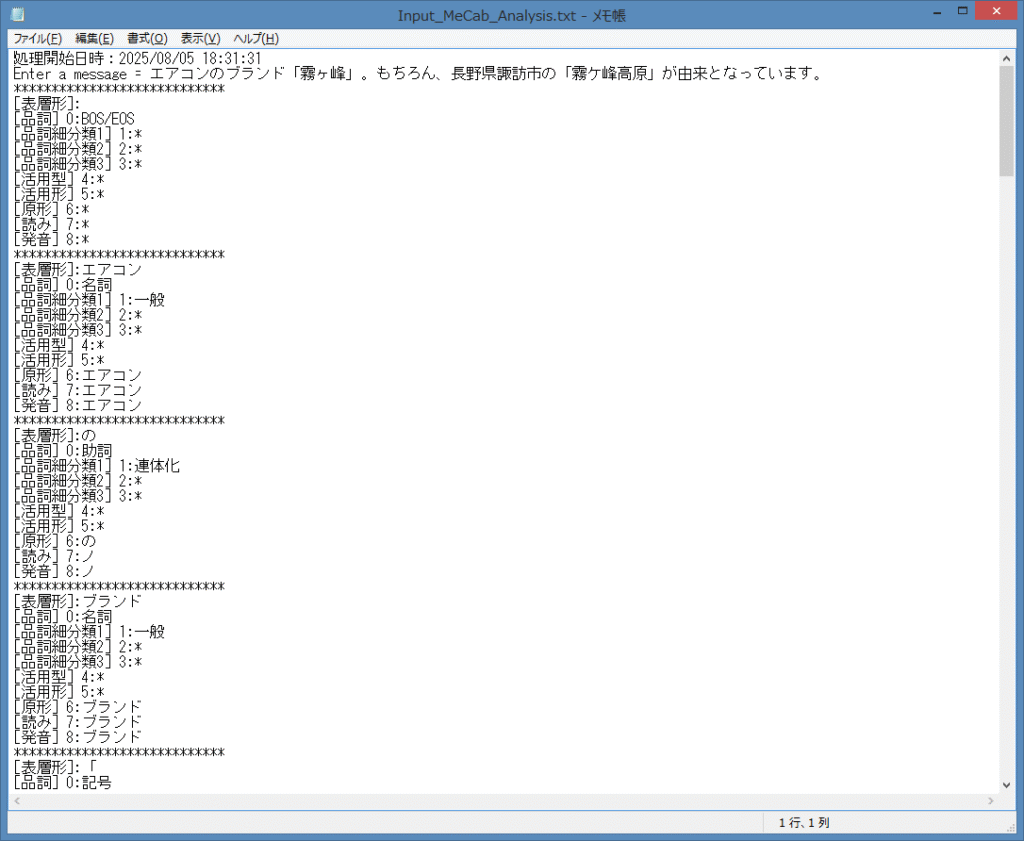
エアコン の ブランド 「 ・・・と、入力されたテキスト文から、それぞれ単語に
分けられて、下記の出力フォーマットで解析されている事が分かりますね。
テキストファイル を、最終行まで下にスクロールしてみます。
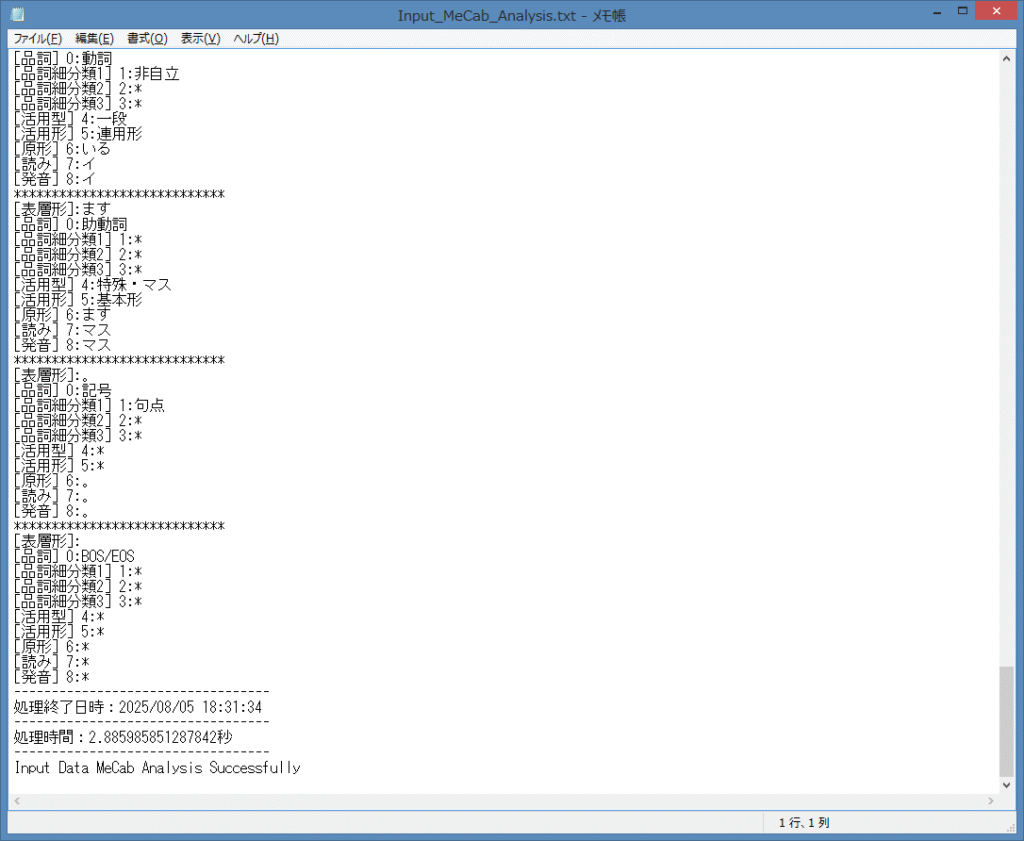
IDLE Shell と同様に、入力されたテキスト文の解析が終了し、処理終了日時と処理時間が
表示されているのを確認する事が出来ました。
まとめ
今回は、前回のWordCloudの生成ツールでも登場した形態素解析について、ソース例と実行例を
紹介して、もう少し深堀りをしてみました。
WordCloud処理
形態素解析器と、WordCloudの処理の順番と役割を振り返ります。
- 形態素解析器:各単語の品詞や活用などを解析・判別して抽出
- WordCloud:単語ごとに出現頻度をカウントします
- WordCloud:出現頻度に応じて、サイズを変更して単語を描画します
今回、紹介したように形態素解析器で、テキスト文から、それぞれ単語に分けられて、
出力フォーマットで解析されている事について、理解が出来たと思います。
WordCloudの処理では、解析された単語(指定した品詞)ごとに出現頻度をカウントし、
出現頻度に応じて、サイズを変更して描画している事は、前回の記事で紹介しました。
次回は、形態素解析器(janome)について、深堀りをする記事を紹介しようと思います。
基本的には、形態素解析器(MeCab)の解析処理と似ていると思われます。

- イラスト:いらすとや より引用


コメント