

前回の記事では、便利なツールとして、Pythonで、QRコードの生成ツールを紹介しました。
今回も同じく便利なツールとして、Pythonで、WordCloudの生成ツールを紹介します。
WordCloud(ワードクラウド/テキストマイニング)
WordCloudは、テキストや文章から単語の出現頻度に応じて、文字の大きさを変えて
視覚的に表示する手法(テキストマイニング)になります。
これにより、テキスト内で最も重要な単語(キーワード)を、直感的に把握することが出来ます。
出現頻度の高い単語程、大きく表示されるため、テキストの内容やテーマを素早く
理解するのに役立ちます。
数年前、某テレビ局のニュース番組では、WordCloudを利用して、今話題のキーワードを
抽出して可視化する事で、視聴者の関心を集めていた記憶が有ります。

日本語は非サポート
WordCloudは、日本語をサポートしていないので、日本語用の形態素解析ライブラリーを
インストールする必要があります。
また、日本語フォントを指定する必要があります。
Windowsの場合は 、C:\Windows\Fonts にインストール済みのフォントが格納されています。

指定したいフォントを右クリックして、プロパティを表示すると、フォントのファイル名が
確認出来ます。
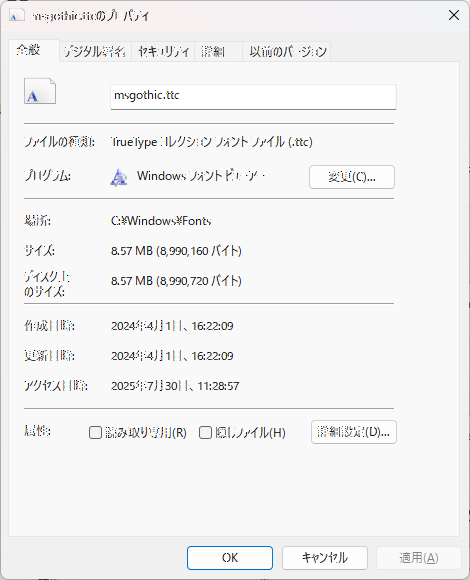
上記は、MS ゴシック 標準フォント(msgothic.ttc)のプロパティを表示しています。
Pythonのソースで、C:\Windows\Fonts\msgothic.ttc のように、指定して下さい。
日本語フォントの場所が分からない場合や、Windows以外の場合は、無料で使える
IPA Fontがあるので、こちらをダウンロードして解凍して下さい。

形態素解析(分かち書き)
WordCloudを実装する際に、前提処理を行うのが、形態素解析になります。
形態素解析は、自然言語のテキストデータをいくつかの単位に分け、各単語の品詞や活用などを
解析・判別して取り出す処理です。
形態素は、言語で意味を持つ最小単位にする事です。
テキストを形態素に分割する処理は、分かち書き(tokenization)とも呼ばれており、
こちらの方が、聞き覚えの有る方もいると思います。
形態素解析器(ソフト/エンジン)
形態素解析は、実際に形態素解析器(ソフト/エンジン)を利用して、各単語の品詞や
活用などを解析・判別して取り出します。
日本語の形態素解析器(ソフト/エンジン)として、有名なのは下記になります。
- ChaSen(茶筌):2012年に奈良先端科学技術大学院大学松本研究室で開発
- JUMAN:2014年に京都大学黒橋・褚・村脇研究室で開発
- KAKASI(かかし):Namazu等の全文検索エンジンと組み合わせで用いられる
- KyTea(キューティー):京都テキスト解析ツールキット
- MeCab(和布蕪):Google 日本語入力開発者の一人である工藤拓氏によって開発
- Janome(蛇の目):Python用の形態素解析エンジン
- Kagome(籠目):Go用の形態素解析エンジン
辞書 (dictionary)
品詞や活用形の特定は、辞書 (dictionary) を活用して行うのが一般的です。
日本語の形態素解析用の辞書として、有名なのは下記になります。
- ipadic:ChaSen用の辞書 → IPA 品詞体系をもとに設計
- UniDic:MeCab用の辞書
- NAIST-jdic:ChaSen、MeCab用の辞書
- JUMAN用の辞書 → 益岡・田窪文法をもとに設計
形態素解析の詳細については、下記を参照して下さい。

WordCloud処理
形態素解析器と、WordCloudの処理の順番と役割を簡単に紹介します。
- 形態素解析器:各単語の品詞や活用などを解析・判別して抽出
- WordCloud:単語ごとに出現頻度をカウントします
- WordCloud:出現頻度に応じて、サイズを変更して単語を描画します
Python パッケージ(ライブラリ)のインストール
WordCloudに関する、パッケージ(ライブラリ)をインストールします。
もし、関連するパッケージ(ライブラリ)がインストールされていない状態で、
ツールやアプリを実行すると、下記のようにエラーとなりますので、ご注意下さい。
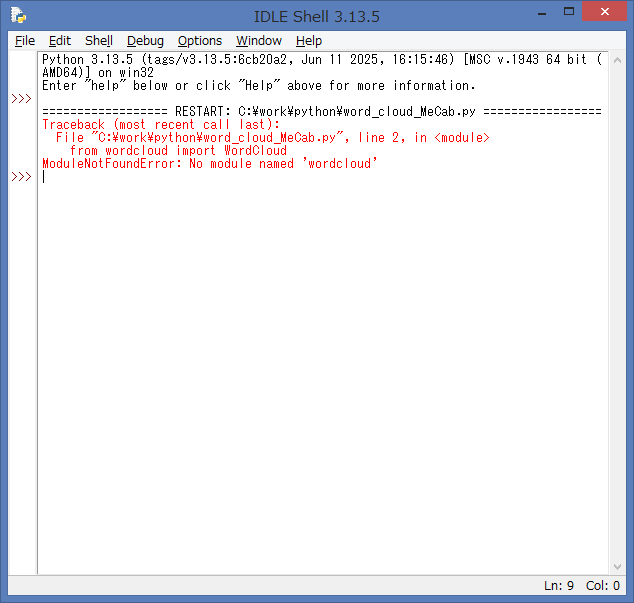
WordCloud ライブラリのインストール
先ずは、WordCloud 本体のライブラリをインストールをしてみます。
いつものように、コマンドプロンプト または PowerShell を起動します。
下記のコマンドで、インストール済みのライブラリを確認します。
python -m pip list
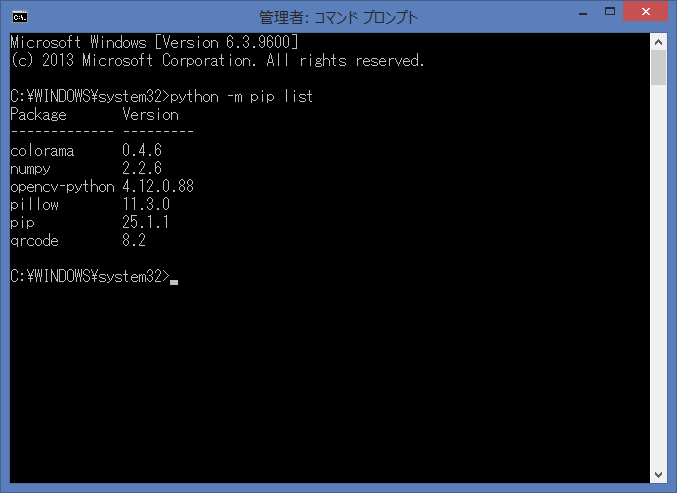
WordCloud 本体のライブラリ名は、全て小文字:wordcloud になります。
下記のコマンドで、インストールします。
python -m pip install wordcloud
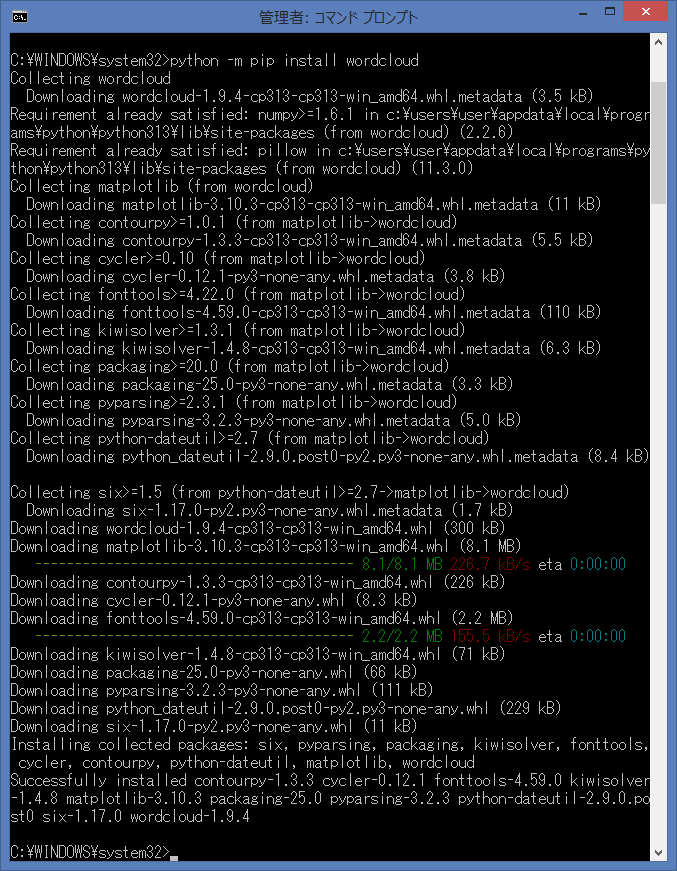
再度、python -m pip list で、インストール済みのライブラリを確認します。
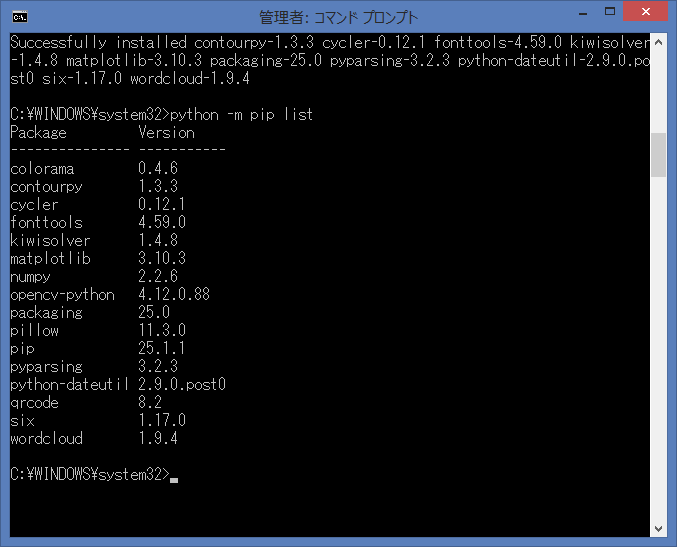
WordCloud 本体がインストールされていることが、確認出来ました。
本体と一緒に、WordCloud で利用される様々なライブラリもインストールされています。
- six
- pyparsing
- packaging
- kiwisolver
- fonttools
- cycler
- contourpy
- python-dateutil
- matplotlib
WordCloud ライブラリ インストール時のエラー
上記では、WordCloud ライブラリが無事にインストールされましたが、他のWindows
パソコンで、インストールした際に、下記のようなエラーが発生した事が有ります。
Visual Studio BuildTools がインストールされていない場合、エラーが発生するようです。
解決方法として、Visual Studio BuildTools のリンクより、Visual Studio ダウンロード
サイトにアクセスしてみて下さい。
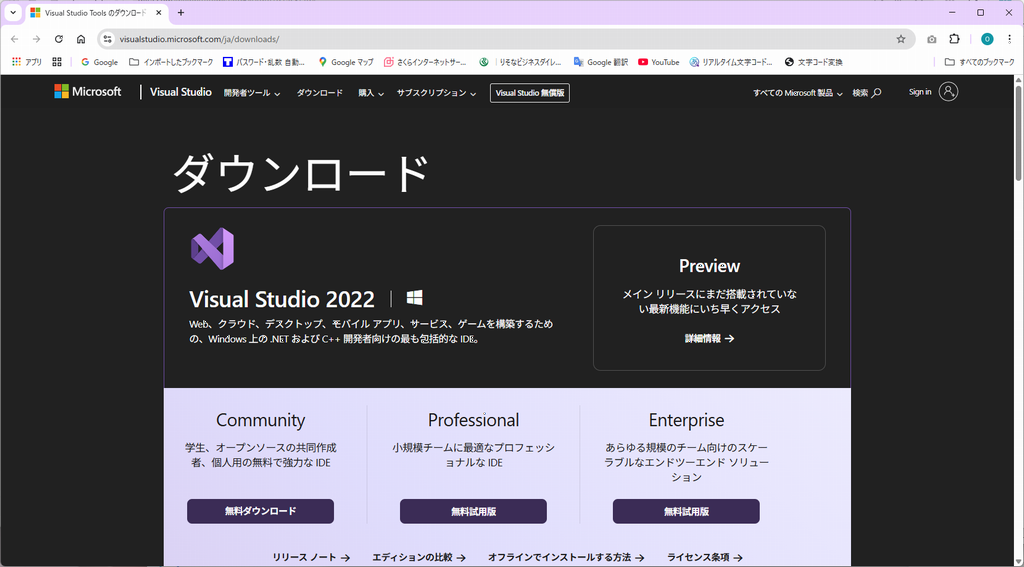
上記のような画面が表示されますので、下にスクロールしてみて下さい。
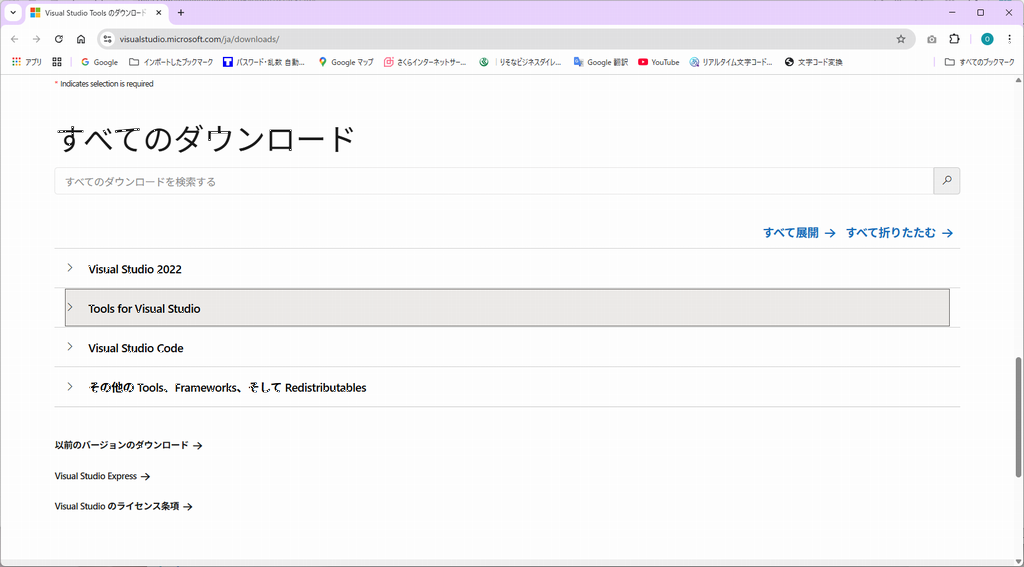
Tools for Visual Studio をクリックして、内容を確認してみて下さい。
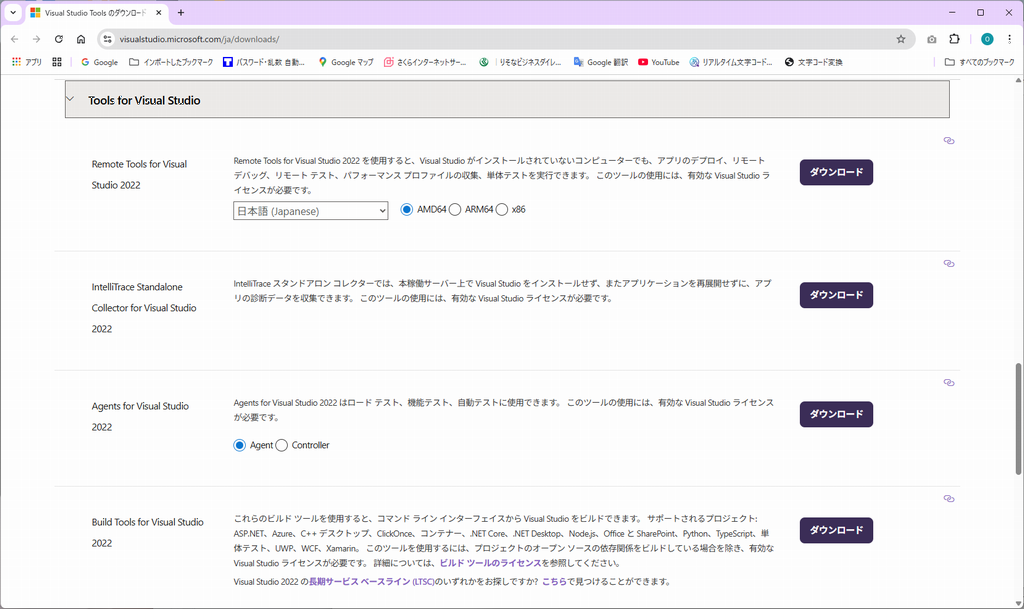
上記の Build Tools for Visual Studio 2022 をダウンロードして、お手元のWindows
パソコンにインストールした後、WordCloud ライブラリをインストールしてみて下さい。
形態素解析器(MeCab/Janome)のインストール
WordCloud 本体がインストールされたので、日本語用の形態素解析ライブラリーを
インストールしてみましょう。
Pythonで良く利用される形態素解析器の2種類:MeCab、Janomeをインストールします。
先ずは、MeCab からインストールしてみます。
コマンドは、下記になります。
python -m pip install mecab
次に、Janomeをインストールします。
コマンドは、下記になります。
python -m pip install janome
形態素解析器の2種類:MeCab、Janomeがインストールされている事が確認出来ました。
WordCloud 生成ツール
WordCloud の生成に必要な、Pythonライブラリがインストールされましたので、
実際に、WordCloudの生成ツールを開発していきます。
統合開発環境(IDLE)の起動
いつものように、Python開発向けに、統合開発環境(IDLE)を起動しましょう。
IDLE Shell より、新規画面を起動します。
WordCloud 生成ソース例
実際に使える、WordCloud 生成ツールを開発していきましょう。
まだ、スクレイピングの開発を紹介する前なので、今回は、保存しているテキスト文を読み込んで、
- 形態素解析器:各単語の品詞や活用などを解析・判別して抽出
- WordCloud:単語ごとに出現頻度をカウントします
- WordCloud:出現頻度に応じて、サイズを変更して単語を描画します
の処理手順で、WordCloud 生成ツールを実施してみます。
テキスト文の例
保存するテキスト文として、今回は、【アラジンと魔法のランプ】を例としました。
参考としたサイトは、下記になります。
夜の砂漠でジャファーと名乗る男は手下の泥棒がある物を持ってくるのを待っていた。 そして、それを利用してランプのある魔法の洞窟を呼び出した。 洞窟が言うには「入れるのはダイヤの原石(内側に清らかな心を持つ者)のみ」だが、「ダイヤの原石」でなかった泥棒は閉じ込められてしまった。 前述の話を聞いたジャファーは「ダイヤの原石」を探そうと企んだ。 砂漠の王国アグラバーに暮らす、両親を失い貧しくも清らかな心を持った青年アラジンはいつか宮殿で豪華な暮らしをすることを夢見ていた。 一方、婚約に嫌気がさして王宮を抜け出そうとしたジャスミン王女は一番の親友・ラジャーの制止を無視してまで家出を決意する。 そんなある日、市場でジャスミンは泥棒の濡れ衣を着せられたところをアラジンに助けられたことで心を通わせる。 だが、アラジンは王女をさらおうとした盗賊と間違えられて捕まり、牢屋に入れられてしまう。 それは王国の支配を企む国務大臣のジャファーが、入る者を厳しく選ぶ魔法の洞窟から「ダイヤの原石」として選ばれたアラジンに、 洞窟の奥にある不思議な魔法のランプを取って来させるための策略だった。 ジャファーはみすぼらしい老人の姿に扮装して牢屋に現れると、ランプを取って来ることを約束させるのと引き換えに、アラジンを脱獄させる。 魔法の洞窟の中で出会った魔法の絨毯の協力でランプを手に入れたものの、アブーがうっかり「ランプ以外の物を触れてはいけない」という掟を破ってしまったため、 洞窟は暴走し、さらにジャファーに裏切られたアラジンは洞窟の中に閉じ込められてしまう。 だが、相棒の猿アブーのおかげでランプがジャファーの手に渡ることは阻止できた。 さらにアラジンはひょんなことから自らランプを擦ったところ、ランプの魔人ジーニーの主人となる。 ジーニーの力でなんとか脱出し、「どんな願いも3つだけ叶えてあげよう」とジーニーに言われたアラジンは、自由を求めるジーニーに対し 「最後の願いで君を自由にする」と約束しつつ、1つ目の願いとして、王子としか結婚が許されていないジャスミンとの恋を叶えるため アリ・アバブア王子に変身することを願い、王宮へと向かう。 頑固なジャスミンは、アリ王子も今までの求婚者達と同じだと思い、まったく相手にしなかったのだが、 「一緒に広い世界を見に行こう」という誘いに乗って魔法の絨毯で世界中を旅するうちに惹かれていく。 途中で口を滑らせた不注意からアラジンの正体がバレそうになるものの、アラジンがとっさに「自分もお城の生活が嫌で、 時々平民に変装して抜け出している」と誤魔化したことでジャスミンは共感を抱き、両想いとなる。 その頃、ランプを手に入れ損なったジャファーは自らの魔力でサルタンを操り、ジャスミンと結婚して王位に就こうとしていた。 そこへアリ王子として現れたアラジンがジャスミンやサルタンに瞬く間に気に入られていくのを邪魔に思ったジャファーは、 アリ王子を暗殺しようと目論んで、部下を使いアラジンを捕まえる。 捕まったアラジンは顔に白い手拭いを巻かれて口を塞がれて声を出せなくされ[注 1]、手足を重り付きの鎖で縛りあげられ、海の底に沈められてしまう。 重りの重さで海底に沈むアラジンは呼吸ができなくなり気を失うが、偶然にもランプが手に触れたことで入浴中のジーニーが現れる。 ジーニーは気絶しかけるアラジンに2つ目の願いごとをするように言うと、アラジンは無事命を救われた。 それと同時にアラジンとジーニーは固い友情で結ばれた。 アリ王子の暗殺に失敗した上に暗躍がバレたジャファーは失脚し、その犯行を暴いたアリ王子はジャスミンの結婚相手として大々的に告知される。 順風満帆な未来が待つかに見えるアラジンだったが、ジーニーの魔法が解けて王子でないことがばれたらジャスミンに嫌われてしまうと不安を感じ、 ジーニーに「君を自由にはできない」と言い出す。 それを聞いたジーニーは怒ってランプの中に引き籠ってしまう。 ジーニーに「本当のことを告げろ」と教えられたアラジンは遠慮なく本当のことをジャスミンに告げるため彼女の元へ向かうが、 その隙を突かれてジャファーの手下のイアーゴにランプを奪われてしまう。 イアーゴからランプを渡されてジーニーの新たな主人となったジャファーが、1つ目の願いでアグラバーの支配者になり、 ジャスミンが相手が支配者であろうがどうしても逆らうことから2つ目の願いで自分を世界一の魔法使いにする。 さらにジャファーは魔法でジャスミン達をいいようにする上にアラジンを元の姿に戻して冬山へ追放してしまう。 アラジンはジーニーを自由にしなかったことを後悔し、絨毯の助けを借りてアグラバーに戻る。 そして、アグラバーの危機を救うべくジャファーに戦いを挑むが、手強い魔法を操り、遂には大蛇に変身したジャファーに巻き付かれて絞め殺されそうになる。 ジャファーの手強い魔法に圧倒されて追い詰められるアラジンはジーニーを見つめて策を閃き、「世界一の魔法使いとして我は世界で一番強い」と 主張するジャファーに対して「ジーニーこそが本当に世界で一番強い」と煽り返す。 それを聞いて今の自分は実質的には世界で二番目であるという事に気づいたジャファーは、最後の願いで真の世界最強の存在=ジーニーになることを願う。 赤いジーニーとなって最強の力を得たジャファーだったが、それはジーニーから教えられていたランプの魔人の制約である 「脅威の力を持つ代わりに自由がない」ことを逆手にとったアラジンの作戦であった。 アラジンの罠に嵌った結果、ジャファーはイアーゴを巻き添えにして専用のランプの中に閉じ込められ、ジーニーに砂漠の彼方へ投げ飛ばされ追放された。 ジャファーとの戦いを終えてアグラバーの平和を取り戻した後、アラジンはジャスミンに嘘をついたことを謝罪して反省し、 最後の願いでジーニーをランプから解放させて自由の身にする。 アラジンのアグラバーを救った勇気に感動したサルタンはジャスミンとの婚約を認め、自由になったジーニーはアラジンと別れて旅立ち、 最後に幸せにアラジンとジャスミンは結ばれた。
せっかく、形態素解析器の2種類:MeCab、Janomeがインストールされているので、
生成ソースもMeCab と Janome の2種類を開発して、比較してみましょう。
MeCabを利用したソース例
それでは、MeCab を利用したソースを紹介します。
# ライブラリのインポート
from wordcloud import WordCloud
import MeCab
import matplotlib.pyplot as plt
from datetime import datetime as dt
import time
import cv2
infile = 'C:/work/python/data/aladdin.txt'
outfile = 'C:/work/python/data/aladdin_MeCab.png'
j_font = 'C:/Windows/Fonts/HGRME.TTC'
try:
# 開始時間
start_time = time.time()
tdatetime = dt.now()
print("処理開始日時:", tdatetime.strftime('%Y/%m/%d %H:%M:%S'))
# テキストの読み込み
with open(infile, "r", encoding="utf-8") as f:
text = f.read()
# 単語の分割
# オプション:辞書は形態素解析器ChaSen用の辞書を採用
tagger = MeCab.Tagger ("-Ochasen")
# 形態素解析
node = tagger.parseToNode(text)
word_list = []
word = ""
while node is not None:
# node.feature:品詞(名詞、形容詞)を取得
word_type = node.feature.split(",")[0]
if word_type in ["名詞", "形容詞"]:
# 表層形の取得
word_list.append(node.surface)
node = node.next # 書き忘れると無限ループになるので注意
word = " ".join(word_list)
# ストップワードを設定
stop_words = ["それ", "ところ", "よう", "そう", "ため", "うち", "こと", "そこ"]
# Windowsにインストールされているフォントを指定
wc = WordCloud(width=800, height=600, background_color='white',
font_path=j_font, stopwords=set(stop_words)).generate(word)
# 画像を保存
wc.to_file(outfile)
plt.figure(figsize=(18,10))
plt.axis("off")
plt.imshow(wc)
# plt.show()
# 終了時間
end_time = time.time()
# 差分
dif_time = end_time - start_time
# 終了時間
tdatetime = dt.now()
print("----------------------------------")
print("処理終了日時:", tdatetime.strftime('%Y/%m/%d %H:%M:%S'))
print("----------------------------------")
print("処理時間:", dif_time , "秒")
print("----------------------------------")
print("WordCloud Make Data Successfully")
img = cv2.imread(outfile)
cv2.imshow("Aladdin WordCloud(MeCab)", img)
cv2.waitKey(0)
except KeyboardInterrupt:
pass
finally:
pass
ソースの解説
from wordcloud import WordCloud
import MeCab
import matplotlib.pyplot as plt
from datetime import datetime as dt
import time
import cv2
こちらは、先程、インストールしたWordCloud、 MeCab、matplotlibや、前回の記事で
画像処理としてインストールしたOpenCVを利用が出来るように、先頭文でライブラリ環境を
インポートしています。
MeCab は、mecabライブラリをインストールしていますが、import mecab と小文字を
指定するとエラーとなりますので、ご注意下さい。
infile = 'C:/work/python/data/aladdin.txt'
outfile = 'C:/work/python/data/aladdin_MeCab.png'
j_font = 'C:/Windows/Fonts/HGRME.TTC'
こちらでは、保存したテキスト文の場所、WordCloudで作成した画像の保存先、
日本語フォントの場所を指定しています。
上記で紹介しましたIPA Fontをダウンロードした場合は、解凍先とフォント名を指定して下さい。
保存場所については、お手元のパソコンのフォルダ構成に合わせて、修正して下さい。
start_time = time.time()
tdatetime = dt.now()
print("処理開始日時:", tdatetime.strftime('%Y/%m/%d %H:%M:%S'))
こちらは、WordCloud 生成処理の開始時間を出力しています。
ツール起動時に汎用的に使えるので、今後も多くのソースで利用しています。
with open(infile, "r", encoding="utf-8") as f:
text = f.read()
上記で指定した、テキスト文を読み込んで、textに代入しています。
テキスト文は、utf-8 の文字コードで保存していますので、文字コードを指定して開いています。
tagger = MeCab.Tagger ("-Ochasen")
node = tagger.parseToNode(text)
こちらは、MeCab のTaggerメソッドを利用して、辞書を指定しています。
“Chasen” という方法で、単語を分けて出力(-Oオプション)の設定をしています。
WordCloud 生成処理には、”-Ochasen” を利用しますが、他の方法も有るようです。
while node is not None:
word_type = node.feature.split(",")[0]
if word_type in ["名詞", "形容詞"]:
word_list.append(node.surface)
node = node.next
word = " ".join(word_list)
node.feature.split(“,”)[0] は、形態素解析した文字列の品詞を word_type に代入しています。
word_type の品詞が、”名詞” と “形容詞” のみ抽出しています。
読み込んだテキスト文を、最後まで形態素解析して、wordに挿入しています。
stop_words = ["それ", "ところ", "よう", "そう", "ため", "うち", "こと", "そこ"]
wc = WordCloud(width=800, height=600, background_color='white',
font_path=j_font, stopwords=set(stop_words)).generate(word)
最後まで形態素解析した内容を、実際にWordCloud で画像を生成しています。
画像の幅、高さ、背景の色、フォント、除外言語(stop words)を指定しています。
wc.to_file(outfile)
plt.figure(figsize=(18,10))
plt.axis("off")
plt.imshow(wc)
実際にWordCloud で画像を生成した後、matplotlib を利用して画像を保存しています。
figureメソッドで、保存する画像の大きさを指定しています。
axis(“off”)メソッドで、目盛りを非表示にしています。
end_time = time.time()
dif_time = end_time - start_time
tdatetime = dt.now()
print("----------------------------------")
print("処理終了日時:", tdatetime.strftime('%Y/%m/%d %H:%M:%S'))
print("----------------------------------")
print("処理時間:", dif_time , "秒")
print("----------------------------------")
print("WordCloud Make Data Successfully")
こちらは、WordCloud 生成処理の終了時間を出力しています。
ツール終了時に汎用的に使えるので、今後も多くのソースで利用しています。
img = cv2.imread(outfile)
cv2.imshow("Aladdin WordCloud(MeCab)", img)
cv2.waitKey(0)
こちらでは、OpenCVの機能を利用して、保存したWordCloud の画像の読み込みと
画像の表示(タイトル指定)をしています。
MeCabを利用したWordCloudソースの実行例
実際に、ソースを起動して、WordCloud を生成してみましょう。
作成したソース画面の上部のタブメニューより、Run → Run Module を選択するか、
F5キーを押下して、ツールを起動します。
ツールを動かして、エラーが無ければ、IDLE Shell には、処理時間と
処理結果が表示されます。
別の画面で、WordCloud の画像がポップアップされていることが
分かると思います。

Janomeを利用したソース例
次に、Janome を利用したソースを紹介します。
# ライブラリのインポート
from wordcloud import WordCloud
from janome.tokenizer import Tokenizer
import matplotlib.pyplot as plt
from datetime import datetime as dt
import time
import cv2
infile = 'C:/work/python/data/aladdin.txt'
outfile = 'C:/work/python/data/aladdin_janome.png'
j_font = 'C:/Windows/Fonts/HGRME.TTC'
try:
# 開始時間
start_time = time.time()
tdatetime = dt.now()
print("処理開始日時:", tdatetime.strftime('%Y/%m/%d %H:%M:%S'))
# テキストの読み込み
with open(infile, "r", encoding="utf-8") as f:
text = f.read()
#単語の分割
tokenizer = Tokenizer()
# 形態素解析
tokens = tokenizer.tokenize(text)
word_list = []
word = ""
for token in tokens:
pos = token.part_of_speech.split(',')[0]
if pos in ['名詞', '形容詞']:
word_list.append(token.surface)
node = node.next # 書き忘れると無限ループになるので注意
word = " ".join(word_list)
# ストップワードを設定
stop_words = ["それ", "ところ", "よう", "そう", "ため", "うち", "こと", "そこ"]
# Windowsにインストールされているフォントを指定
wc = WordCloud(width=800, height=600, background_color='white',
font_path=j_font, stopwords=set(stop_words)).generate(word)
# 画像を保存
wc.to_file(outfile)
plt.figure(figsize=(18,10))
plt.axis("off")
plt.imshow(wc)
# plt.show()
# 終了時間
end_time = time.time()
# 差分
dif_time = end_time - start_time
# 終了時間
tdatetime = dt.now()
print("----------------------------------")
print("処理終了日時:", tdatetime.strftime('%Y/%m/%d %H:%M:%S'))
print("----------------------------------")
print("処理時間:", dif_time , "秒")
print("----------------------------------")
print("WordCloud Make Data Successfully")
img = cv2.imread(outfile)
cv2.imshow("Aladdin WordCloud(janome)", img)
cv2.waitKey(0)
except KeyboardInterrupt:
pass
finally:
pass
ソースの解説
from wordcloud import WordCloud
from janome.tokenizer import Tokenizer
import matplotlib.pyplot as plt
from datetime import datetime as dt
import time
import cv2
こちらは、先程、インストールしたWordCloud、 janome、matplotlibや、前回の記事で
画像処理としてインストールしたOpenCVを利用が出来るように、先頭文でライブラリ環境を
インポートしています。
infile = 'C:/work/python/data/aladdin.txt'
outfile = 'C:/work/python/data/aladdin_janome.png'
j_font = 'C:/Windows/Fonts/HGRME.TTC'
こちらでは、MeCab同様に保存したテキスト文の場所、WordCloudで作成した画像の保存先、
日本語フォントの場所を指定しています。
上記で紹介しましたIPA Fontをダウンロードした場合は、解凍先とフォント名を指定して下さい。
保存場所については、お手元のパソコンのフォルダ構成に合わせて、修正して下さい。
以下は、MeCab同様な処理は、割愛させて頂きますので、janome 特有の処理のみ
解説させて頂きます。
with open(infile, "r", encoding="utf-8") as f:
text = f.read()
tokenizer = Tokenizer()
tokens = tokenizer.tokenize(text)
word_list = []
word = ""
for token in tokens:
pos = token.part_of_speech.split(',')[0]
if pos in ['名詞', '形容詞']:
word_list.append(token.surface)
word = " ".join(word_list)
上記で指定した、テキスト文を読み込んで、textに代入しています。
テキスト文は、utf-8 の文字コードで保存していますので、文字コードを指定して開いています。
Tokenizerのインスタンスを作成して、形態素解析したいテキスト文をtokenizeメソッドで、
tokens へ渡しています。
token.part_of_speech.split(‘,’)[0] のインスタンス変数は、形態素解析した文字列の
品詞を pos に代入しています。
pos の品詞が、”名詞” と “形容詞” のみ抽出しています。
読み込んだテキスト文を、最後まで形態素解析して、wordに挿入しています。
Janomeの内部では、デフォルトユーザー定義辞書のフォーマットは,MeCab 辞書と
同じですので、特に変更する必要は無いと思います。
実際にWordCloud で画像を生成するソースや、matplotlib を利用して画像を保存するソースは、
基本的にMeCabと同様の処理になります。
img = cv2.imread(outfile)
cv2.imshow("Aladdin WordCloud(janome)", img)
cv2.waitKey(0)
こちらでは、OpenCVの機能を利用して、保存したWordCloud の画像の読み込みと
画像の表示(タイトル指定)をしています。
Janomeを利用したWordCloudソースの実行例
実際に、ソースを起動して、WordCloud を生成してみましょう。
作成したソース画面の上部のタブメニューより、Run → Run Module を選択するか、
F5キーを押下して、ツールを動かします。
ツールを動かして、エラーが無ければ、IDLE Shell には、処理時間と
処理結果が表示されます。
別の画面で、WordCloud の画像がポップアップされていることが
分かると思います。

Janome の内部では、MeCab 辞書と同じですが、WordCloud で作成した画像は、違いますね。
しかし、両方共に、単語の出現頻度に応じて、文字の大きさを変えて視覚的に表示しています。
共通な単語(キーワード)が、直感的に把握することが出来ますね。
matplotlib での画像表示について
img = cv2.imread(outfile)
cv2.imshow("Aladdin WordCloud(janome)", img)
cv2.waitKey(0)上記のような OpenCV を利用せず、matplotlib のまま画像を表示することも可能ですが、
実行してみると、少し違和感のある画像が表示されます。
上記の OpenCV の表示箇所のソースを、コメントアウトします。
plt.figure(figsize=(18,10))
plt.axis("off")
plt.imshow(wc)
plt.show()上記の matplotlib を利用したソースの最後に、plt.show()メソッドを追記した後、
Janome を利用したソースを更新してから、WordCloud 生成ツールを実行してみます。

matplotlib の調整を詳細に設定したら、OpenCV 同様にサイズやタイトルも綺麗に表示
することが出来るかもしれませんが、今回は割愛させて頂きます。
まとめ
今回も便利なツールとして、Pythonで、WordCloudの生成ツールを紹介しました。
今ではChatGPTやGemini、Perplexity等のAIツールが簡単に利用出来るので、
WordCloudの需要が少なくなったかもしれません。
しかし、Python、形態素解析器と気軽に利用して、テキストマイニングの実現方法を学び、
経験が出来るチャンスでも有るので、若手エンジニアや年配の方にも楽しんでもらえたらと
思っています。
スクレイピングのツール開発を紹介した後には、インターネットのサイトから、
WordCloud でキーワードを表示する記事を紹介したいと思います。
- イラスト:いらすとや より引用


コメント