

前回の記事では、Pythonでテキストファイルの内容を読み込んだ後、音声ファイルに変換して、
読み上げ処理を行う記事を紹介しました。
今回は、PythonでWebスクレイピング処理した内容を読み込んだ後、音声ファイルに変換して、
読み上げ処理を行う記事を紹介しようと思います。
Webスクレイピング+音声ファイル変換+読み上げ処理
以前の記事で、Yahoo! ニュース を Webスクレイピング処理した記事を紹介しました。
そこで実装したソースを、今回は流用しようと思います。
Yahoo! ニュース を Webスクレイピング処理した記事については、下記を参照して下さい。

ソース例
Yahoo! ニュース を Webスクレイピング処理したソースを流用して、
Webスクレイピング+音声ファイル変換+読み上げ処理を行うソースを紹介します。
import requests
from bs4 import BeautifulSoup
import re
from gtts import gTTS
from pygame import mixer
from datetime import datetime as dt
import time
play_mp3 = "./mp3/yahoo_voice.mp3"
line = "------------------------------------"
date_time = ""
def get_yahoo_news():
# ヤフーニュースのトップページ情報を取得する
URL = "https://www.yahoo.co.jp/"
rest = requests.get(URL)
# BeautifulSoupにヤフーニュースのページ内容を読み込ませる
soup = BeautifulSoup(rest.text, "html.parser")
# ヤフーニュースの見出しとURLの情報を取得して出力する
data_list = soup.find_all(href=re.compile("news.yahoo.co.jp/pickup"))
news_list = "yahoo headline news です。"
i = 0
print("Yahoo! 新着ニュース情報")
print(line)
for data in data_list:
news = data.span.string
i = i + 1
print(str(i) + ":" + news)
news_list += str(i)
news_list += news
date_time = dt.now().strftime('%Y/%m/%d %H:%M:%S')
print(line)
footer(date_time)
news_end = date_time + "現在の yahoo headline news でした。"
news_list += news_end
tts = gTTS(text=news_list, lang='ja', slow=False)
tts.save(play_mp3)
mixer.init()
mixer.music.load(play_mp3)
mixer.music.play()
def header():
print(line)
def footer(date_time):
print(date_time + ' Now !')
print(line)
if __name__ == "__main__":
try:
header()
get_yahoo_news()
except Exception as e:
print("Exception: ", e)
except KeyboardInterrupt:
pass

ソースの解説
では、上記に掲載したソースを解説して行きます。
import requests
from bs4 import BeautifulSoup
import re
from gtts import gTTS
from pygame import mixer
from datetime import datetime as dt
import time
play_mp3 = "./mp3/yahoo_voice.mp3"
こちらは、Webスクレイピング+音声ファイル変換+読み上げ処理を行う為に必要な
ライブラリをインポートしています。
- Requests:Webページ取得用のライブラリ
- BeautifulSoup:Webページ(静的)の情報解析、要素抽出用のライブラリ
- re:正規表現(regex)用のライブラリ
- gTTS:Google翻訳ライブラリで、文字列を音声データ(mp3)に変換します
- pygame:ゲーム開発用ライブラリで、mixer.musicモジュールで、ストリーミング再生
- datetime, time:日付や時間を扱う為の標準ライブラリ
- play_mp3:変換した音声データの保存先(環境に合わせて修正して下さい)
def get_yahoo_news():
# ヤフーニュースのトップページ情報を取得する
URL = "https://www.yahoo.co.jp/"
rest = requests.get(URL)
# BeautifulSoupにヤフーニュースのページ内容を読み込ませる
soup = BeautifulSoup(rest.text, "html.parser")
# ヤフーニュースの見出しとURLの情報を取得して出力する
data_list = soup.find_all(href=re.compile("news.yahoo.co.jp/pickup"))こちらは、Webスクレイピング処理になります。
- rest = requests.get(URL):WebページのURLを指定して、Yahoo! ニュース の情報を取得しています。
- soup = BeautifulSoup() :取得したWebページの情報(HTML)を解析しています。
- data_list = soup.find_all() :Yahoo! ニュース のピックアップ(pickup)の解析と要素の抽出しています。
news_list = "yahoo headline news です。"
i = 0
print("Yahoo! 新着ニュース情報")
print(line)
for data in data_list:
news = data.span.string
i = i + 1
print(str(i) + ":" + news)
news_list += str(i)
news_list += news
date_time = dt.now().strftime('%Y/%m/%d %H:%M:%S')
print(line)
footer(date_time)
news_end = date_time + "現在の yahoo headline news でした。"
news_list += news_end
こちらは、“news.yahoo.co.jp/pickup” が含まれる要素を抽出した情報から、
ループ処理を利用して、1項目毎にニュース内容を取り出しています。
- news_list = “yahoo headline news です。”:音声データの開始用に、文字列を設定しています。
- for data in data_list::抽出した Yahoo! ニュース のピックアップ(pickup)のデータをループ処理で、1項目毎にニュース内容を取り出しています。
- news = data.span.string:<span>タグの内容を、文字列として取得しています。
- news_list += str(i):ニュース番号を、文字列に設定しています。
- news_list += news:ニュース内容を、文字列に設定しています。
- date_time = dt.now().strftime(‘%Y/%m/%d %H:%M:%S’):現在の日時を、フォーマットに合わせて、文字列に設定しています。→ 例:2025/10/16 09:04:29
- news_end = date_time + “現在の yahoo headline news でした。”:音声データの終了用に、文字列を設定しています。
tts = gTTS(text=news_list, lang='ja', slow=False)
tts.save(play_mp3)
mixer.init()
mixer.music.load(play_mp3)
mixer.music.play()
こちらは、Webスクレイピング処理した内容を読み込んだ Yahoo! ニュース と、音声データの
開始用/終了用の文字列を音声ファイルに変換して、読み上げ処理を行っています。
- tts = gTTS(text=news_list, lang=’ja’, slow=False):文字列を音声ファイルに変換しています。
- tts.save(play_mp3):変換した音声ファイルを、音声データ(mp3)で保存しています。
- mixer.music.load(play_mp3):保存した音声データ(mp3)を、メモリ上にロードしています。
- mixer.music.play():ロードした音声データを、ストリーミング再生(読み上げ)を処理しています。
実行例
実際にソースを起動して、Webスクレイピング+音声ファイル変換+読み上げ処理を
実行してみましょう。
作成したソースの上部のタブメニューより、Run → Run Module を選択するか、
F5キーを押下して、ソースを実行します。
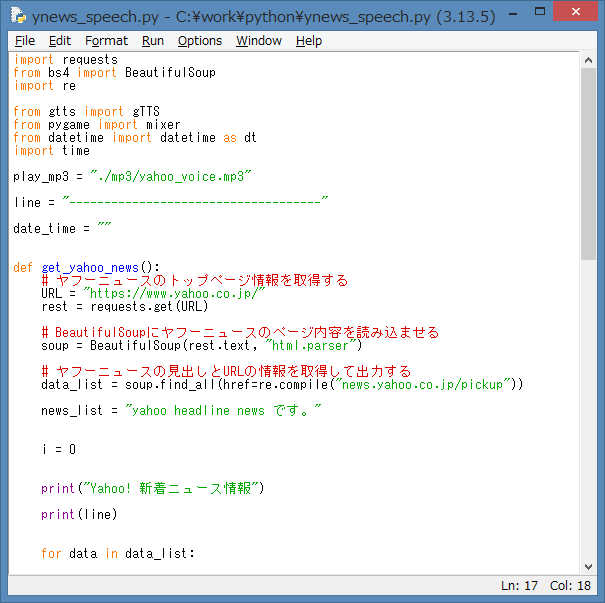
ソースを起動して、エラーが無ければ、IDLE Shell には、Yahoo! ニュース より
Webスクレイピング処理した新着ニュース情報が表示されます。
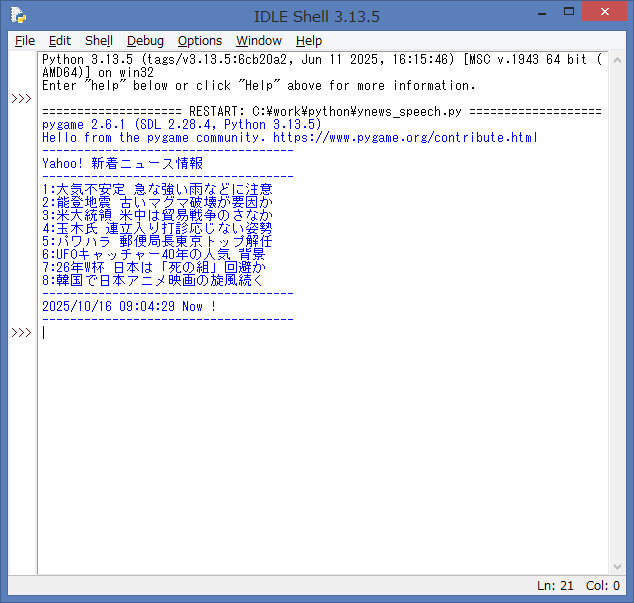
続いて、Webスクレイピング処理した内容を、音声ファイルに変換した後、
読み上げ処理を行います。
不自然な読み上げ
実際に、Webスクレイピング処理した内容を、そのまま読み上げ処理を行うと
とても不自然で、表現や数字の間違いも有ります。
7:26年W杯 日本は「死の組」回避か
上記の内容では、7:26年W杯 の箇所を、726年W杯 と間違って読み上げています。
そこで、語尾を補足する処理をソースに記述する事で、より丁寧な読み上げ処理を行います。
Webスクレイピング+音声ファイル変換+読み上げ処理:補足編
Webスクレイピング処理した内容を、そのまま読み上げ処理を行うと、
とても不自然で、表現や数字の間違いも有りるので、補足してみます。
ソース例:語尾を補足
語尾を補足する処理を、ソースに追記してみます。
import requests
from bs4 import BeautifulSoup
import re
from gtts import gTTS
from pygame import mixer
from datetime import datetime as dt
import time
play_mp3 = "./mp3/yahoo_voice.mp3"
line = "------------------------------------"
date_time = ""
def get_yahoo_news():
# ヤフーニュースのトップページ情報を取得する
URL = "https://www.yahoo.co.jp/"
rest = requests.get(URL)
# BeautifulSoupにヤフーニュースのページ内容を読み込ませる
soup = BeautifulSoup(rest.text, "html.parser")
# ヤフーニュースの見出しとURLの情報を取得して出力する
data_list = soup.find_all(href=re.compile("news.yahoo.co.jp/pickup"))
news_list = "yahoo headline news です。"
news_number = "番目のニュースは、 "
news_space = "です。 "
i = 0
print("Yahoo! 新着ニュース情報")
print(line)
for data in data_list:
news = data.span.string
i = i + 1
print(str(i) + ":" + news)
news_list += str(i)
news_list += news_number
news_list += news
news_list += news_space
date_time = dt.now().strftime('%Y/%m/%d %H:%M:%S')
print(line)
footer(date_time)
news_end = date_time + "現在の yahoo headline news でした。"
news_list += news_end
tts = gTTS(text=news_list, lang='ja', slow=False)
tts.save(play_mp3)
mixer.init()
mixer.music.load(play_mp3)
mixer.music.play()
def header():
print(line)
def footer(date_time):
print(date_time + ' Now !')
print(line)
if __name__ == "__main__":
try:
header()
get_yahoo_news()
except Exception as e:
print("Exception: ", e)
except KeyboardInterrupt:
pass
ソースの解説:補足箇所
では、上記に掲載したソースの補足箇所を解説して行きます。
news_list = "yahoo headline news です。"
news_number = "番目のニュースは、 "
news_space = "です。 "
i = 0
print("Yahoo! 新着ニュース情報")
print(line)
for data in data_list:
news = data.span.string
i = i + 1
print(str(i) + ":" + news)
news_list += str(i)
news_list += news_number
news_list += news
news_list += news_space
こちらは、1項目毎にニュース内容を取り出した時に、特定の文字列を補足しています。
- news_number = “番目のニュースは、 ”:ニュース番号 の後に補足する内容を、文字列に設定しています。スペースを入れることで、読み上げの間を開けています。
- news_space = “です。 ”:ニュース内容 の後に補足する内容を、文字列に設定しています。スペースを入れることで、読み上げの間を開けています。
- news_list += news_number:ニュース番号 の後に、news_number を追加しています。
- news_list += news_space:ニュース内容 の後に、news_space を追加しています。
実行例:語尾を追加
実際にソースを起動して、Webスクレイピング+音声ファイル変換+読み上げ処理を
実行してみましょう。
作成したソースの上部のタブメニューより、Run → Run Module を選択するか、
F5キーを押下して、ソースを実行します。
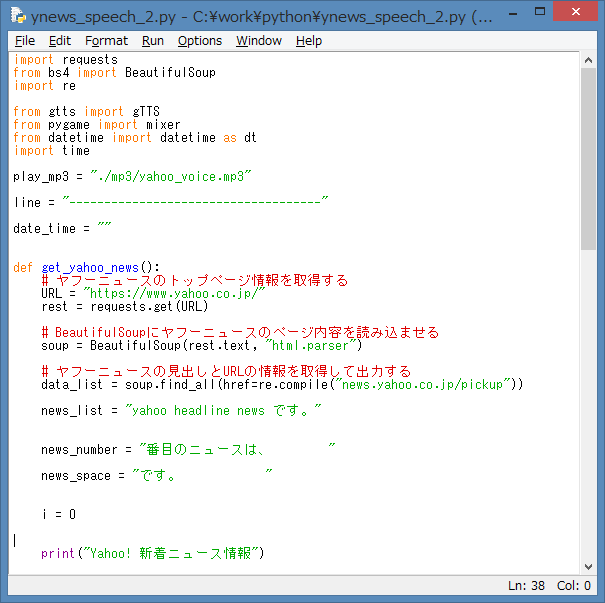
ソースを起動して、エラーが無ければ、IDLE Shell には、Yahoo! ニュース より
Webスクレイピング処理した新着ニュース情報が表示されます。
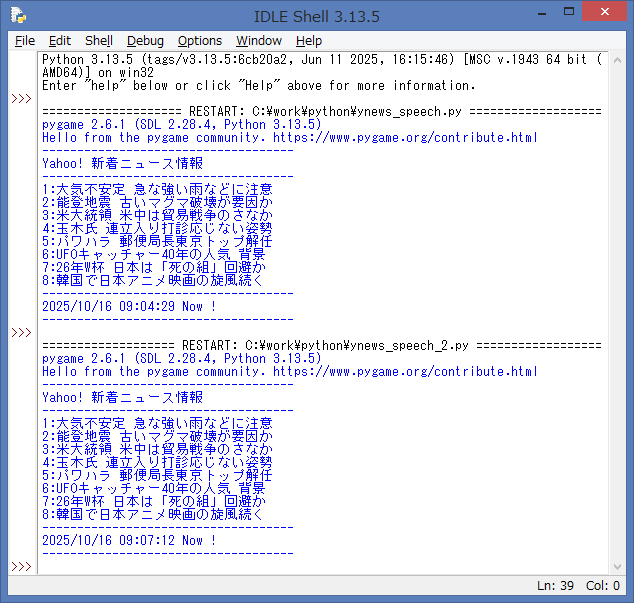
続いて、Webスクレイピング処理した内容を、音声ファイルに変換した後、
読み上げ処理を行います。
今回は、如何でしょうか?
7:26年W杯 日本は「死の組」回避か
今度は、7番目のニュースは、26年W杯… と読み上げている事が確認出来ると思います。
最初の読み上げ内容よりも、随分と自然な内容に聞こえて来たように思われます。
音声ファイルに変換した後の読み上げ処理は、学習したAI機能を搭載している訳では無いので、
多少、不自然に聞こえる部分は有りますが、十分理解が出来る内容だと思います。
gTTS (Google Translate’s Text-to-Speech)ライブラリは、とても優秀ですね。

まとめ
今回は、Yahoo! ニュース を Webスクレイピング処理した後、音声ファイルに変換して、
読み上げ処理を行う記事を紹介しました。
Webスクレイピング処理した内容を、そのまま読み上げ処理を行うと、とても不自然で、
表現や数字の間違いも有ります。
学習したAI機能を搭載している訳では無いので、語尾を補足する処理をソースに記述する事で、
より丁寧な読み上げ処理を行います。
次回は、他のWebサイトのWebスクレイピング+音声ファイル変換+読み上げ処理を行う
記事を紹介しようと思います。

- イラスト:いらすとや より引用


コメント