

前回の記事では、Yahoo! ニュース を Webスクレイピング処理した後、音声ファイルに
変換して、読み上げ処理を行う記事を紹介しました。

今回は、他のニュースサイトについて、Webスクレイピング処理した内容を読み込んだ後、
音声ファイルに変換して、読み上げ処理を行う記事を紹介しようと思います。
音声ファイル変換+読み上げ処理:応用編
今回は、下記の3つのニュース Webサイトに対して新着情報を取得後、音声ファイルに
変換して、読み上げ処理を行います。
- 日本経済新聞 Webサイト:Webスクレイピング + 音声ファイル変換 + 読み上げ処理
- 読売新聞 Webサイト:Webスクレイピング + 音声ファイル変換 +読み上げ処理
- 毎日新聞 Webサイト:RSSフィード + 音声ファイル変換 + 読み上げ処理
ソース例:日本経済新聞 Webサイト スクレイピング
先ずは、日本経済新聞 Webサイト で Webスクレイピング+音声ファイル変換+読み上げ処理
を行うソースを紹介します。
ソース例
Yahoo! ニュース を Webスクレイピング+音声ファイル変換+読み上げ処理 したソースを
流用して、日本経済新聞 Webサイト を Webスクレイピング+音声ファイル変換+読み上げ処理
するソースを紹介します。
import requests
from bs4 import BeautifulSoup
from gtts import gTTS
from pygame import mixer
from datetime import datetime as dt
import time
play_mp3 = "./mp3/nikkei_voice.mp3"
line = "------------------------------------"
date_time = ""
def get_nikkei_news():
# 日本経済新聞の速報を取得する
URL = "https://www.nikkei.com/news/category/"
rest = requests.get(URL)
# BeautifulSoupに日本経済新聞の新着ニュース内容を読み込ませる
soup = BeautifulSoup(rest.text, "html.parser")
# 日本経済新聞の速報の見出しとURLの情報を取得して出力する
data_list = soup.find_all(class_="fauxBlockLink_ftpicz8", limit=8)
news_list = "日本経済新聞 headline news です。"
news_number = "番目のニュースは、 "
news_space = "です。 "
i = 0
print("日本経済新聞 新着ニュース情報")
print(line)
for data in data_list:
news = data.text
i = i + 1
print(str(i) + ":" + news)
news_list += str(i)
news_list += news_number
news_list += news
news_list += news_space
date_time = dt.now().strftime('%Y/%m/%d %H:%M:%S')
print(line)
footer(date_time)
news_end = date_time + "現在の日本経済新聞 headline news でした。"
news_list += news_end
tts = gTTS(text=news_list, lang='ja', slow=False)
tts.save(play_mp3)
mixer.init()
mixer.music.load(play_mp3)
mixer.music.play()
def header():
print(line)
def footer(date_time):
print(date_time + ' Now !')
print(line)
if __name__ == "__main__":
try:
header()
get_nikkei_news()
except Exception as e:
print("Exception: ", e)
except KeyboardInterrupt:
pass
ソースの解説
では、上記に掲載したソースを解説して行きます。
import requests
from bs4 import BeautifulSoup
from gtts import gTTS
from pygame import mixer
from datetime import datetime as dt
import time
play_mp3 = "./mp3/nikkei_voice.mp3"
こちらは、Webスクレイピング+音声ファイル変換+読み上げ処理を行う為に必要な
ライブラリをインポートしています。
- Requests:Webページ取得用のライブラリ
- BeautifulSoup:Webページ(静的)の情報解析、要素抽出用のライブラリ
- gTTS:Google翻訳ライブラリで、文字列を音声データ(mp3)に変換します
- pygame:ゲーム開発用ライブラリで、mixer.musicモジュールで、ストリーミング再生
- datetime, time:日付や時間を扱う為の標準ライブラリ
- play_mp3:変換した音声データの保存先(環境に合わせて修正して下さい)
def get_nikkei_news():
# 日本経済新聞の速報を取得する
URL = "https://www.nikkei.com/news/category/"
rest = requests.get(URL)
# BeautifulSoupに日本経済新聞の新着ニュース内容を読み込ませる
soup = BeautifulSoup(rest.text, "html.parser")
# 日本経済新聞の速報の見出しとURLの情報を取得して出力する
data_list = soup.find_all(class_="fauxBlockLink_ftpicz8", limit=8)
こちらは、Webスクレイピング処理になります。
- rest = requests.get(URL):WebページのURLを指定して、日本経済新聞 の情報を取得しています。
- soup = BeautifulSoup() :取得したWebページの情報(HTML)を解析しています。
- data_list = soup.find_all() :日本経済新聞 の class_=”fauxBlockLink_ftpicz8″ の解析と8件の要素の抽出(limit=8)しています。
日本経済新聞 の速報の見出しを見てみましょう。
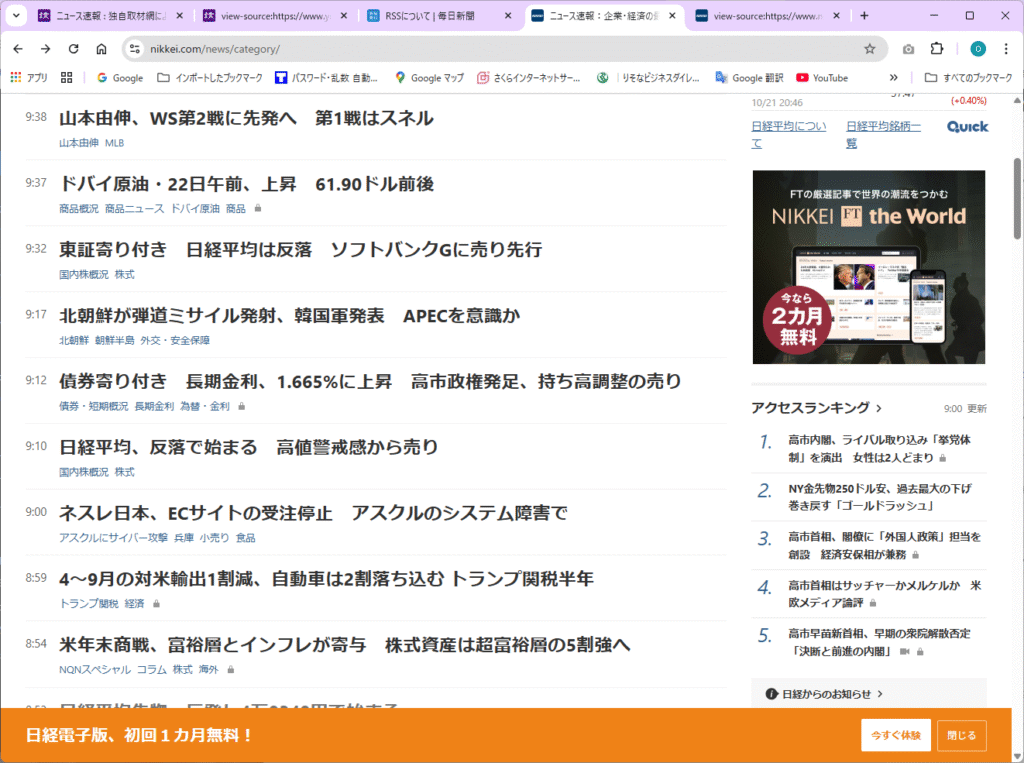
日本経済新聞 の速報の見出しのソースも見てみましょう。
こちらは、class_=”fauxBlockLink_ftpicz8″ の付近の情報になります。
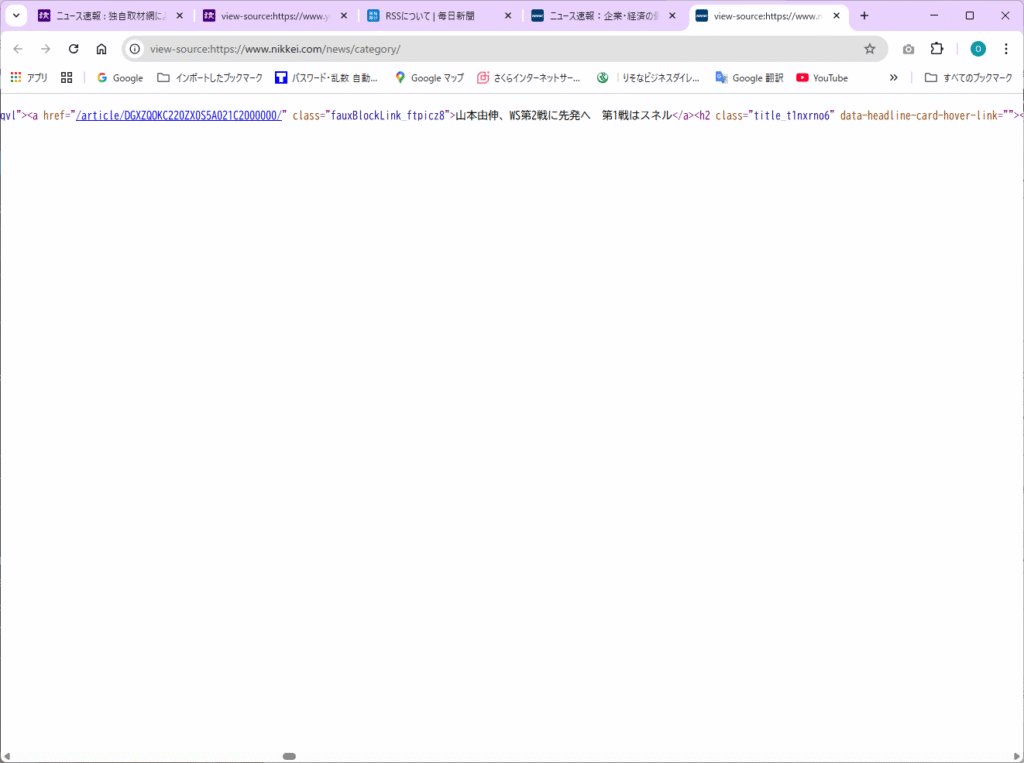
実際の日本経済新聞 の速報の見出しとURLの情報は、下記を参照して下さい。

news_list = "日本経済新聞 headline news です。"
news_number = "番目のニュースは、 "
news_space = "です。 "
i = 0
print("日本経済新聞 新着ニュース情報")
print(line)
for data in data_list:
news = data.text
i = i + 1
print(str(i) + ":" + news)
news_list += str(i)
news_list += news_number
news_list += news
news_list += news_space
date_time = dt.now().strftime('%Y/%m/%d %H:%M:%S')
print(line)
footer(date_time)
news_end = date_time + "現在の日本経済新聞 headline news でした。"
news_list += news_end
こちらは、class_=”fauxBlockLink_ftpicz8″ の解析と要素を抽出した情報から、
ループ処理を利用して、1項目毎にニュース内容を取り出しています。
- news_list = “日本経済新聞 headline news です。”:音声データの開始用に、文字列を設定しています。
- for data in data_list::抽出した 日本経済新聞 の “fauxBlockLink_ftpicz8” のデータをループ処理で、1項目毎にニュース内容を取り出しています。
- news = data.text:dataの内容を、文字列として取得しています。
- news_list += str(i):ニュース番号を、文字列に設定しています。
- news_list += news:ニュース内容を、文字列に設定しています。
- date_time = dt.now().strftime(‘%Y/%m/%d %H:%M:%S’):現在の日時を、フォーマットに合わせて、文字列に設定しています。→ 例:2025/10/22 09:41:54
- news_end = date_time + “現在の日本経済新聞 headline news でした。”:音声データの終了用に、文字列を設定しています。
tts = gTTS(text=news_list, lang='ja', slow=False)
tts.save(play_mp3)
mixer.init()
mixer.music.load(play_mp3)
mixer.music.play()
こちらは、Webスクレイピング処理した内容を読み込んだ 日本経済新聞 と、音声データの
開始用/終了用の文字列を音声ファイルに変換して、読み上げ処理を行っています。
- tts = gTTS(text=news_list, lang=’ja’, slow=False):文字列を音声ファイルに変換しています。
- tts.save(play_mp3):変換した音声ファイルを、音声データ(mp3)で保存しています。
- mixer.music.load(play_mp3):保存した音声データ(mp3)を、メモリ上にロードしています。
- mixer.music.play():ロードした音声データを、ストリーミング再生(読み上げ)を処理しています。
実行例
実際に、ソースを起動して、日本経済新聞 Webサイト を Webスクレイピング+音声ファイル変換
+読み上げ処理 を実行してみましょう。
作成したソースの上部のタブメニューより、Run → Run Module を選択するか、
F5キーを押下して、ソースを実行します。
ソースを起動して、エラーが無ければ、IDLE Shell には、日本経済新聞 Webサイト より
Webスクレイピング処理した新着ニュースが表示されます。
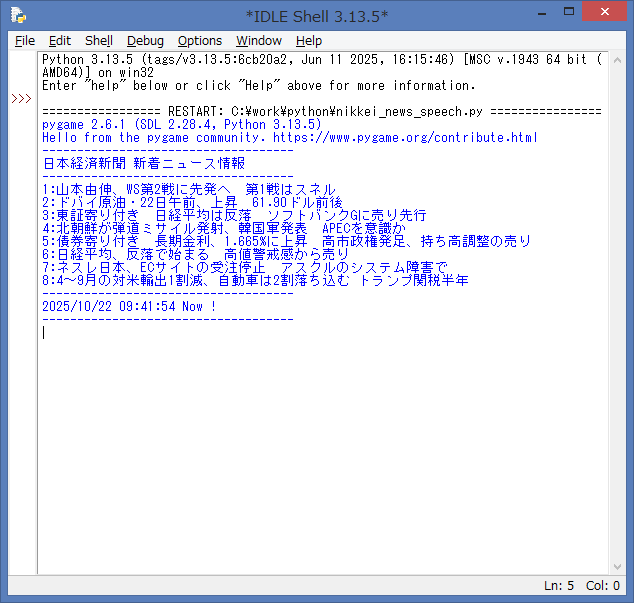
続いて、Webスクレイピング処理した内容を、音声ファイルに変換した後、
読み上げ処理 を行います。

ソース例:読売新聞 Webサイト スクレイピング
次に、読売新聞 Webサイト で Webスクレイピング+音声ファイル変換+読み上げ処理を
行うソースを紹介します。
ソース例
Yahoo! ニュース を Webスクレイピング+音声ファイル変換+読み上げ処理 したソースを
流用して、読売新聞 Webサイト を Webスクレイピング+音声ファイル変換+読み上げ処理
するソースを紹介します。
import requests
from bs4 import BeautifulSoup
from gtts import gTTS
from pygame import mixer
from datetime import datetime as dt
import time
play_mp3 = "./mp3/yomiuri_voice.mp3"
line = "------------------------------------"
date_time = ""
def get_yomiuri_news():
# 読売新聞の新着ニュース情報を取得する
URL = "https://www.yomiuri.co.jp/news/"
rest = requests.get(URL)
# BeautifulSoupに読売新聞の新着ニュース内容を読み込ませる
soup = BeautifulSoup(rest.text, "html.parser")
# 読売新聞の新着ニュースの見出しとURLの情報を取得して出力する
data_list = soup.select("div.news-top-latest__list-item__inner > h3", limit=8)
news_list = "読売新聞 headline news です。"
news_number = "番目のニュースは、 "
news_space = "です。 "
i = 0
print("読売新聞 新着ニュース情報")
print(line)
for data in data_list:
news = data.text
i = i + 1
print(str(i) + ":" + news)
news_list += str(i)
news_list += news_number
news_list += news
news_list += news_space
date_time = dt.now().strftime('%Y/%m/%d %H:%M:%S')
print(line)
footer(date_time)
news_end = date_time + "現在の読売新聞 headline news でした。"
news_list += news_end
tts = gTTS(text=news_list, lang='ja', slow=False)
tts.save(play_mp3)
mixer.init()
mixer.music.load(play_mp3)
mixer.music.play()
def header():
print(line)
def footer(date_time):
print(date_time + ' Now !')
print(line)
if __name__ == "__main__":
try:
header()
get_yomiuri_news()
except Exception as e:
print("Exception: ", e)
except KeyboardInterrupt:
pass
ソースの解説
では、上記に掲載したソースを解説して行きます。
import requests
from bs4 import BeautifulSoup
from gtts import gTTS
from pygame import mixer
from datetime import datetime as dt
import time
play_mp3 = "./mp3/yomiuri_voice.mp3"
こちらは、Webスクレイピング+音声ファイル変換+読み上げ処理を行う為に必要な
ライブラリをインポートしています。
- Requests:Webページ取得用のライブラリ
- BeautifulSoup:Webページ(静的)の情報解析、要素抽出用のライブラリ
- gTTS:Google翻訳ライブラリで、文字列を音声データ(mp3)に変換します
- pygame:ゲーム開発用ライブラリで、mixer.musicモジュールで、ストリーミング再生
- datetime, time:日付や時間を扱う為の標準ライブラリ
- play_mp3:変換した音声データの保存先(環境に合わせて修正して下さい)
def get_yomiuri_news():
# 読売新聞の新着ニュース情報を取得する
URL = "https://www.yomiuri.co.jp/news/"
rest = requests.get(URL)
# BeautifulSoupに読売新聞の新着ニュース内容を読み込ませる
soup = BeautifulSoup(rest.text, "html.parser")
# 読売新聞の新着ニュースの見出しとURLの情報を取得して出力する
data_list = soup.select("div.news-top-latest__list-item__inner > h3", limit=8)
こちらは、Webスクレイピング処理になります。
- rest = requests.get(URL):WebページのURLを指定して、読売新聞 の情報を取得しています。
- soup = BeautifulSoup() :取得したWebページの情報(HTML)を解析しています。
- data_list = soup.select() :読売新聞 の “div.news-top-latest__list-item__inner > h3” の解析と8件の要素の抽出(limit=8)しています。<h3>タグを解析して抽出しています。
読売新聞 Webサイト の見出しを見てみましょう。
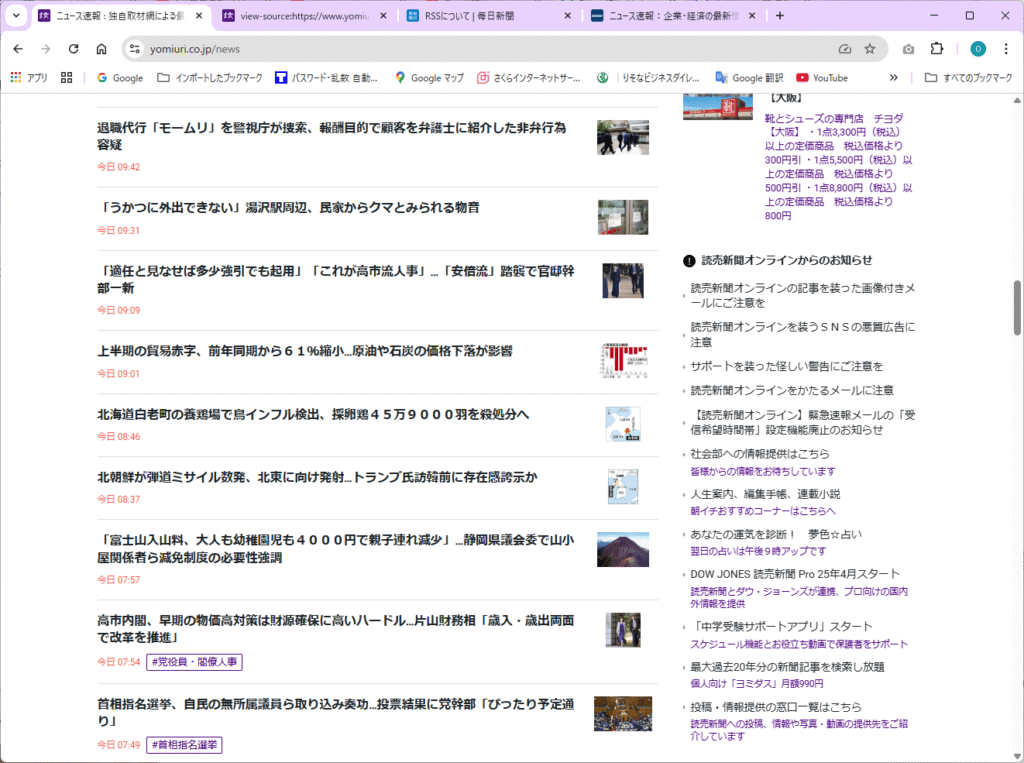
読売新聞 Webサイト の見出しのソースも見てみましょう。
こちらは、 “div.news-top-latest__list-item__inner > h3” 付近の情報です。
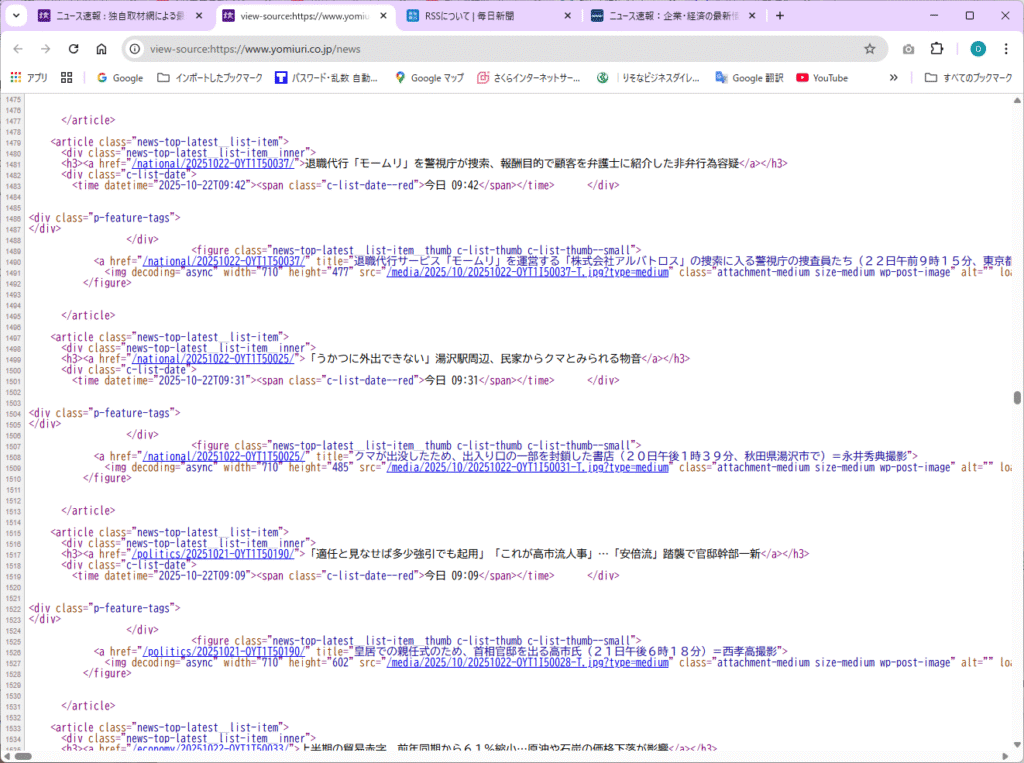
実際の 読売新聞 Webサイト の見出しとURLの情報は、下記を参照して下さい。

news_list = "読売新聞 headline news です。"
news_number = "番目のニュースは、 "
news_space = "です。 "
i = 0
print("読売新聞 新着ニュース情報")
print(line)
for data in data_list:
news = data.text
i = i + 1
print(str(i) + ":" + news)
news_list += str(i)
news_list += news_number
news_list += news
news_list += news_space
date_time = dt.now().strftime('%Y/%m/%d %H:%M:%S')
print(line)
footer(date_time)
news_end = date_time + "現在の読売新聞 headline news でした。"
news_list += news_end
こちらは、“div.news-top-latest__list-item__inner > h3” の解析と要素を抽出した
情報から、ループ処理を利用して、1項目毎にニュース内容を取り出しています。
- news_list = “読売新聞 headline news です。”:音声データの開始用に、文字列を設定しています。
- for data in data_list::抽出した 読売新聞 の “div.news-top-latest__list-item__inner > h3” のデータをループ処理で、1項目毎にニュース内容を取り出しています。
- news = data.text:dataの内容を、文字列として取得しています。
- news_list += str(i):ニュース番号を、文字列に設定しています。
- news_list += news:ニュース内容を、文字列に設定しています。
- date_time = dt.now().strftime(‘%Y/%m/%d %H:%M:%S’):現在の日時を、フォーマットに合わせて、文字列に設定しています。→ 例:2025/10/22 09:44:38
- news_end = date_time + “現在の読売新聞 headline news でした。”:音声データの終了用に、文字列を設定しています。
tts = gTTS(text=news_list, lang='ja', slow=False)
tts.save(play_mp3)
mixer.init()
mixer.music.load(play_mp3)
mixer.music.play()
こちらは、Webスクレイピング処理した内容を読み込んだ 読売新聞 と、音声データの
開始用/終了用の文字列を音声ファイルに変換して、読み上げ処理を行っています。
- tts = gTTS(text=news_list, lang=’ja’, slow=False):文字列を音声ファイルに変換しています。
- tts.save(play_mp3):変換した音声ファイルを、音声データ(mp3)で保存しています。
- mixer.music.load(play_mp3):保存した音声データ(mp3)を、メモリ上にロードしています。
- mixer.music.play():ロードした音声データを、ストリーミング再生(読み上げ)を処理しています。
実行例
実際に、ソースを起動して、読売新聞 Webサイト を Webスクレイピング+音声ファイル変換
+読み上げ処理 を実行してみましょう。
作成したソースの上部のタブメニューより、Run → Run Module を選択するか、
F5キーを押下して、ソースを実行します。
ソースを起動して、エラーが無ければ、IDLE Shell には、読売新聞 Webサイト より
Webスクレイピング処理した新着ニュースが表示されます。
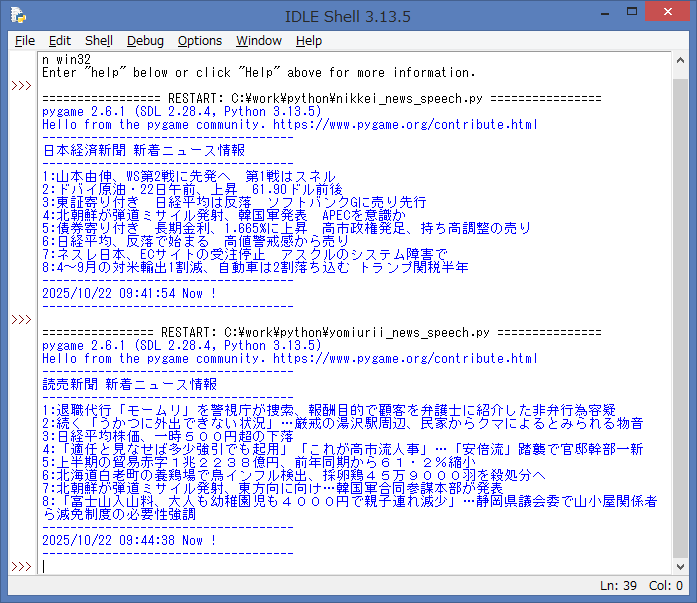
続いて、Webスクレイピング処理した内容を、音声ファイルに変換した後、
読み上げ処理 を行います。
gTTS (Google Translate’s Text-to-Speech)ライブラリは、とても優秀に音声ファイルに
変換してくれていますが、多少、読み方を間違える事も有ります。
上記のニュースの8番目の内容で、冒頭部分を注目して下さい。
- 誤:富士山入山料 → ふじさん いりやま りょう
- 正:富士山入山料 → ふじさん にゅうざん りょう
日本語って難しいですよね!!
これも、愛嬌だと思って、記事の紹介を続けますね。

ソース例:毎日新聞 RSS フィード解析
今度は、毎日新聞 Webサイト の RSSフィード を利用します。
Webスクレイピング処理と異なり、フィード解析+音声ファイル変換+読み上げ処理を行う
ソースを紹介します。
RSSフィード は、既に古い技術なので利用者が減少しているものの、まだ採用している
Webサイト が有りますので、今回、紹介します。
RSS
RSS は、RDF Site Summary/Rich Site Summay/Really Simple Syndicationの略
とも言われ、特定のWebサイトを定期的にチェックする必要なく、更新情報だけを自動的に
受け取れる便利な仕組みです。
XMLを応用したデータ形式の一つで、Webサイト内の新着ページや更新ページのタイトルや
URL、更新日時、要約等を一覧形式で記述することが出来ます。
RSS に関する詳細は、下記のwikipediaのサイトをご参照下さい。
feedparserライブラリのインストール
Webスクレイピング処理では、Requests + BeautifulSoup のライブラリを利用しましたが、
RSSフィード を利用する場合は、feedparserライブラリを利用します。
feedparserライブラリは、RSS 1.0/RSS 2.0/Atom の全てのフォーマットに対応しています。
feedparserライブラリの詳細は、下記のサイトを参照して下さい。

コマンドプロンプト または PowerShell を起動します。
インストール済みのライブラリについては、下記のコマンドで確認が出来ます。
python -m pip list
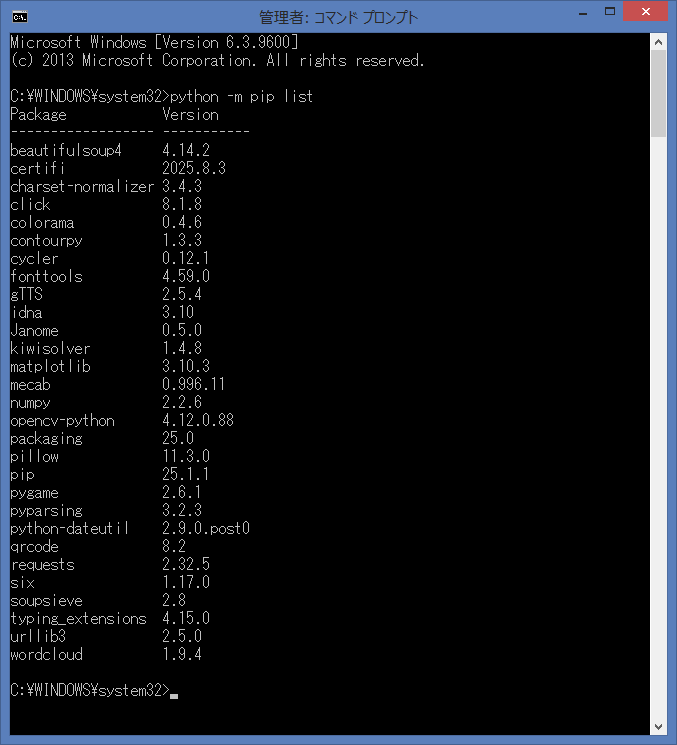
まだ、feedparserライブラリがインストールされていない事が確認出来ました。
では、下記のコマンドで、feedparserライブラリをインストールしてみます。
python -m pip install feedparser
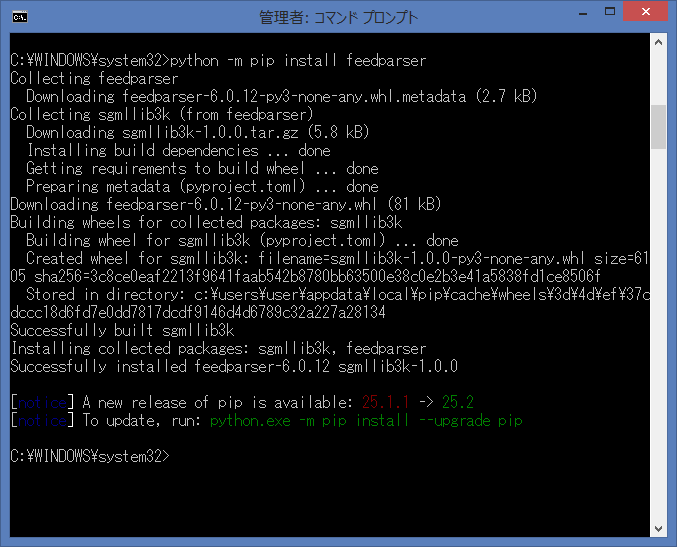
インストール時にエラーが表示されませんでしたので、問題無くインストールされていると
思いますが、再度、インストール済みのライブラリを確認します。
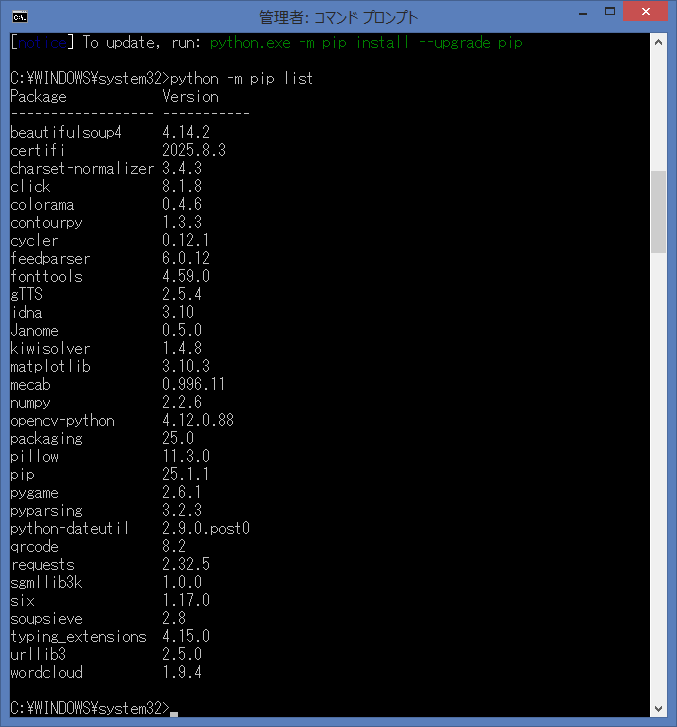
- feedparser:Version 6.0.12
上記のライブラリがインストールされている事が、確認出来ました。
ソース例
毎日新聞 Webサイト の RSSフィード を利用して、フィード解析+音声ファイル変換+
読み上げ処理を行うソースを紹介します。
import feedparser
from gtts import gTTS
from pygame import mixer
from datetime import datetime as dt
import time
play_mp3 = "./mp3/mainichi_rss_voice.mp3"
line = "------------------------------------"
date_time = ""
def get_mainichi_rss_news():
# 毎日新聞サイト RSS Scrape
fd = feedparser.parse("https://mainichi.jp/rss/etc/mainichi-flash.rss")
news_list = "毎日新聞 RSS headline news です。"
news_number = "番目のニュースは、 "
news_space = "です。 "
i = 0
print("毎日新聞 RSS 新着ニュース情報")
print(line)
for entry in fd.entries:
news = entry.title
i = i + 1
print(str(i) + ":" + news)
news_list += str(i)
news_list += news_number
news_list += news
news_list += news_space
if (i > 7):
break
date_time = dt.now().strftime('%Y/%m/%d %H:%M:%S')
print(line)
footer(date_time)
news_end = date_time + "現在の毎日新聞 RSS headline news でした。"
news_list += news_end
tts = gTTS(text=news_list, lang='ja', slow=False)
tts.save(play_mp3)
mixer.init()
mixer.music.load(play_mp3)
mixer.music.play()
def header():
print(line)
def footer(date_time):
print(date_time + ' Now !')
print(line)
if __name__ == "__main__":
try:
header()
get_mainichi_rss_news()
except Exception as e:
print("Exception: ", e)
except KeyboardInterrupt:
pass
ソースの解説
では、上記に掲載したソースを解説して行きます。
import feedparser
from gtts import gTTS
from pygame import mixer
from datetime import datetime as dt
import time
play_mp3 = "./mp3/mainichi_rss_voice.mp3"
こちらは、フィード解析+音声ファイル変換+読み上げ処理を行う為に必要なライブラリを
インポートしています。
- feedparser:フィード解析用のライブラリ
- gTTS:Google翻訳ライブラリで、文字列を音声データ(mp3)に変換します
- pygame:ゲーム開発用ライブラリで、mixer.musicモジュールで、ストリーミング再生
- datetime, time:日付や時間を扱う為の標準ライブラリ
- play_mp3:変換した音声データの保存先(環境に合わせて修正して下さい)
def get_mainichi_rss_news():
# 毎日新聞サイト RSS Scrape
fd = feedparser.parse("https://mainichi.jp/rss/etc/mainichi-flash.rss")
こちらは、RSSフィード解析処理になります。
- fd = feedparser.parset(URL):WebページのURLを指定して、毎日新聞 の RSSフィード の情報を取得しています。
毎日新聞 Webサイト の RSSフィード のWebサイトを見てみましょう。
実際の 毎日新聞 Webサイト の RSSフィード の URLの情報は、下記を参照して下さい。
news_list = "毎日新聞 RSS headline news です。"
news_number = "番目のニュースは、 "
news_space = "です。 "
i = 0
print("毎日新聞 RSS 新着ニュース情報")
print(line)
for entry in fd.entries:
news = entry.title
i = i + 1
print(str(i) + ":" + news)
news_list += str(i)
news_list += news_number
news_list += news
news_list += news_space
if (i > 7):
break
date_time = dt.now().strftime('%Y/%m/%d %H:%M:%S')
print(line)
footer(date_time)
news_end = date_time + "現在の毎日新聞 RSS headline news でした。"
news_list += news_end
こちらは、RSSフィード解析と要素を抽出した情報から、ループ処理を利用して、
1項目毎にニュース内容を取り出しています。
- news_list = “毎日新聞 RSS headline news です。”:音声データの開始用に、文字列を設定しています。
- for entry in fd.entries::解析と抽出した 毎日新聞 RSSフィードのデータをループ処理で、1項目毎にニュース内容を取り出しています。
- news = entry.title:entryのタイトルを、文字列として取得しています。
- news_list += str(i):ニュース番号を、文字列に設定しています。
- news_list += news:ニュース内容を、文字列に設定しています。
- if (i > 7):取り出したニュース項目が、7件を超えて8件目を取り出したら、ループ処理を終了します。
- date_time = dt.now().strftime(‘%Y/%m/%d %H:%M:%S’):現在の日時を、フォーマットに合わせて、文字列に設定しています。→ 例:2025/10/22 09:47:25
- news_end = date_time + “現在の毎日新聞 RSS headline news でした。”:音声データの終了用に、文字列を設定しています。
tts = gTTS(text=news_list, lang='ja', slow=False)
tts.save(play_mp3)
mixer.init()
mixer.music.load(play_mp3)
mixer.music.play()
こちらは、RSSフィード解析した内容を読み込んだ 毎日新聞 と、音声データの
開始用/終了用の文字列を音声ファイルに変換して、読み上げ処理を行っています。
- tts = gTTS(text=news_list, lang=’ja’, slow=False):文字列を音声ファイルに変換しています。
- tts.save(play_mp3):変換した音声ファイルを、音声データ(mp3)で保存しています。
- mixer.music.load(play_mp3):保存した音声データ(mp3)を、メモリ上にロードしています。
- mixer.music.play():ロードした音声データを、ストリーミング再生(読み上げ)を処理しています。
実行例
実際に、ソースを起動して、毎日新聞 Webサイト の RSSフィード を利用して、
フィード解析+音声ファイル変換+読み上げ処理 を実行してみましょう。
作成したソースの上部のタブメニューより、Run → Run Module を選択するか、
F5キーを押下して、ソースを実行します。
ソースを起動して、エラーが無ければ、IDLE Shell には、毎日新聞 Webサイト より
RSSフィード解析処理した新着ニュースが表示されます。
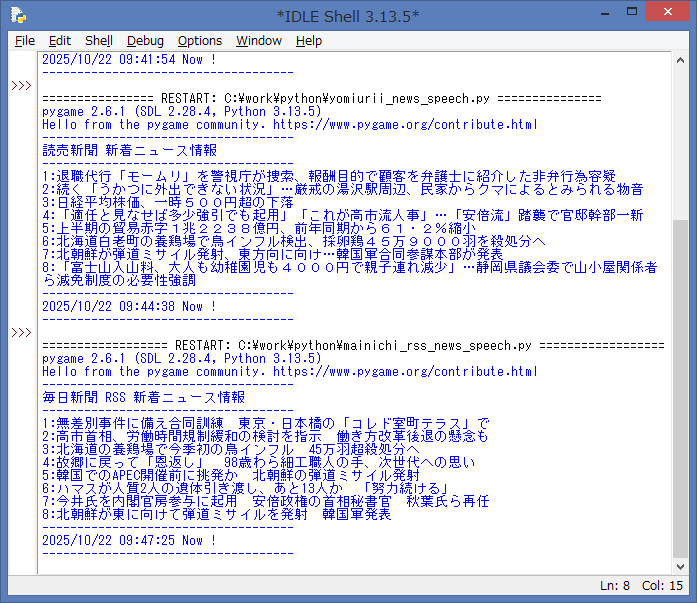
続いて、RSSフィード解析処理した内容を、音声ファイルに変換した後、
読み上げ処理 を行います。

Webスクレイピング/RSSフィード:発展型
今回紹介した3つのWebサイトについて、Webスクレイピング/フィード解析の発展型として、
手作り電光掲示板をYouTubeに公開していますので、こちらも紹介しておきます。
- 日本経済新聞 Webサイト:Webスクレイピング
- 読売新聞 Webサイト:Webスクレイピング
- 毎日新聞 Webサイト:RSSフィード
尚、音声ファイル変換と読み上げ処理は実装していません。
YouTube:電光掲示板
記事で紹介した日時:2025/10/22 09:47:25 に近い動画です。
【開発環境】
- Raspberry Pi3 Modle B+ https://amzn.to/3Z7pLmu
- MAX7219(ドットマトリクス LED) https://amzn.to/3FDfCHs
- Python
- 美咲フォント https://littlelimit.net/misaki.htm
- ライブラリ:BeautifulSoup Requests feedparser
まとめ
今回は、下記の3つのWebサイトに対して内容を取得後、音声ファイルに変換して、
読み上げ処理を紹介しました。
- 日本経済新聞 Webサイト:Webスクレイピング + 音声ファイル変換 + 読み上げ処理
- 読売新聞 Webサイト:Webスクレイピング + 音声ファイル変換 +読み上げ処理
- 毎日新聞 Webサイト:RSSフィード + 音声ファイル変換 + 読み上げ処理
RSSフィード の フィード解析で利用する、feedparserライブラリのインストールと
利用方法も紹介しています。

次回からは、Pythonから少し離れて、Swiftで開発を行う記事を紹介しようと思います。
- イラスト:いらすとや より引用


コメント