

前回の記事では、Webスクレイピング処理を紹介しました。
Yahoo! ニュース(Webページ)から、Webスクレイピング処理を実行して、
ニュースタイトル(8項目)を抽出しました。
今回は、Webスクレイピング処理に加えて、以前、紹介したWordCloud生成を組み合わせて、
対象のWebページから、単語(キーワード)を可視化する記事を紹介しようと思います。
WordCloud生成については、下記の記事を参考にして下さい。

Webスクレイピング+WordCloud生成処理(janome)
Webスクレイピング+WordCloud生成の処理に必要なライブラリは、記事に従って
実施していれば、新たにライブラリのインストールを行う必要は有りません。
ライブラリのインストール
もし、処理に必要なライブラリがインストールされていない場合は、上記の記事を参考にして
ライブラリをインストールしてみて下さい。
処理概要
- 単語(キーワード)を可視化をしたいWebページのURLを入力
- Requestsブジェクトで、対象のWebページから情報を取得
- BeautifulSoupオブジェクトで、取得した情報を解析
- 解析した内容(トピックス)を、Janomeで品詞や活用型に形態素解析
- 形態素解析した結果を、WordCloudで単語ごとに出現頻度をカウント
- 出現頻度に応じて、サイズを変更して単語を描画して、OpenCVで画像を表示
ソース例:janome
それでは、Webスクレイピング+WordCloud生成(janome)の処理が出来る
ソースを紹介します。
import requests
from bs4 import BeautifulSoup
from wordcloud import WordCloud
from janome.tokenizer import Tokenizer
from PIL import Image
import numpy as np
from datetime import datetime as dt
import time
import cv2
outfile = "./data/scraper_wordcloud.png"
line = "----------------------------------"
# URL情報の取得
def scraping(input_url):
try:
# 指定したWEBサイトから情報を取得
html = requests.get(input_url)
# 取得したHTMLテキストをBeautifulSoupオブジェクトにパース(解析)
parse = BeautifulSoup(html.text,'html.parser')
# 条件に合うすべての要素を取得
parse_tag = parse.find_all("p")
topics = []
for text_data in parse_tag:
topics.append(text_data.getText())
print(line)
print("topics")
print(line)
print(topics)
# Attribute Error(要素が存在していない)例外処理
except AttributeError as e:
print("AttributeError:", e)
return None
return topics
# 解析処理
def purse(input_url):
tokenizer = Tokenizer()
words = []
# URL情報の取得
topics = scraping(input_url)
if topics == None:
print("情報を取得できませんでした")
else:
for word in topics:
tokens = tokenizer.tokenize(word)
for token in tokens:
pos = token.part_of_speech.split(',')[0]
if pos in ['名詞', '形容詞']:
words.append(token.surface)
text = ' '.join(words)
# ストップワードを設定
stop_words = [u"あれ", u"これ", u"さん", u"です"]
# Windowsにインストールされているフォントを指定
wordcloud = WordCloud(width=800, height=600, background_color='white',
font_path='./Font/IPAexfont00401/ipaexg.ttf',
stopwords=set(stop_words)).generate(text)
wordcloud.to_file(outfile)
try:
while True:
url = input("Enter URL = ")
url_leng =len(url)
if url_leng == 0:
print("URLを指定して下さい!!")
print(line)
else:
# 開始時間
start_time = time.time()
print(line)
print("処理開始日時:", dt.now().strftime('%Y/%m/%d %H:%M:%S'))
# 解析処理
purse(url)
# 終了時間
end_time = time.time()
# 差分
dif_time = end_time - start_time
# 終了時間
tdatetime = dt.now()
print(line)
print("処理終了日時:", dt.now().strftime('%Y/%m/%d %H:%M:%S'))
print(line)
print("処理時間:", dif_time , "秒")
print(line)
print("WordCloud Make Data Succesfully !!")
print(line)
print("Open scraper_wordcloud.png !!")
print(line)
img = cv2.imread(outfile)
cv2.imshow("input_url_wordcloud", img)
cv2.waitKey(0)
except Exception as e:
print("Exception: ", e)
except KeyboardInterrupt:
pass
Webスクレイピング処理とWordCloud生成処理の詳細なソース解説は、以前の記事で
紹介していますので、今回は省略します。
上記の処理概要を確認頂ければ、ソースを追えると思います。
ソースの実行例:janome
実際に、ソースを起動して、Webスクレイピング+WordCloud生成の処理を実行してみます。
作成したソースの上部のタブメニューより、Run → Run Module を選択するか、
F5キー を押下して、ソースを実行します。
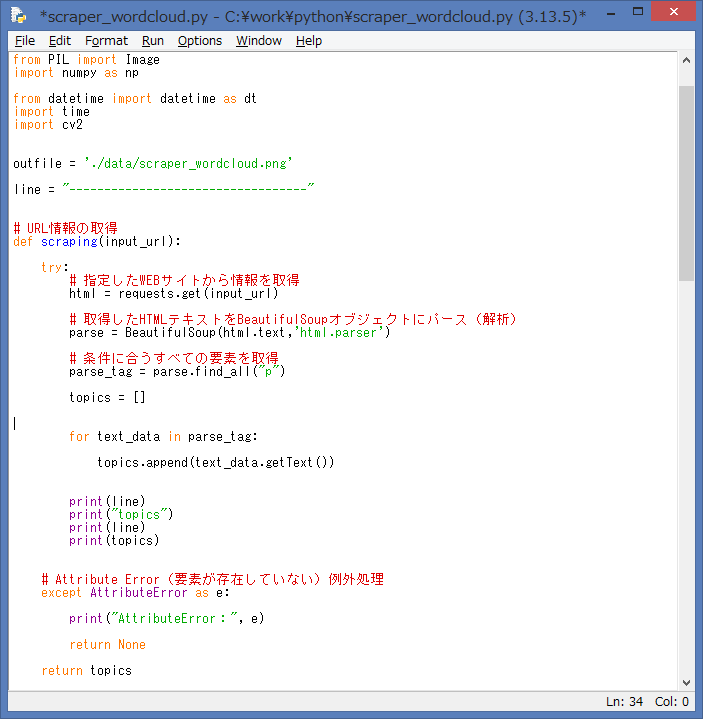
ソースを実行すると、IDLE Shell には、単語(キーワード)を可視化をしたい
WebページのURLの入力を促す内容が表示されます。
では、実際に単語(キーワード)を可視化をするWebページのURLを入力します。
今回は、下記のWebサイトのURLを入力してみます。

この記事を読むタイミングで、対象のWebサイトが存在しない可能性も有りますので、
スクリーンショットを掲載しておきます。
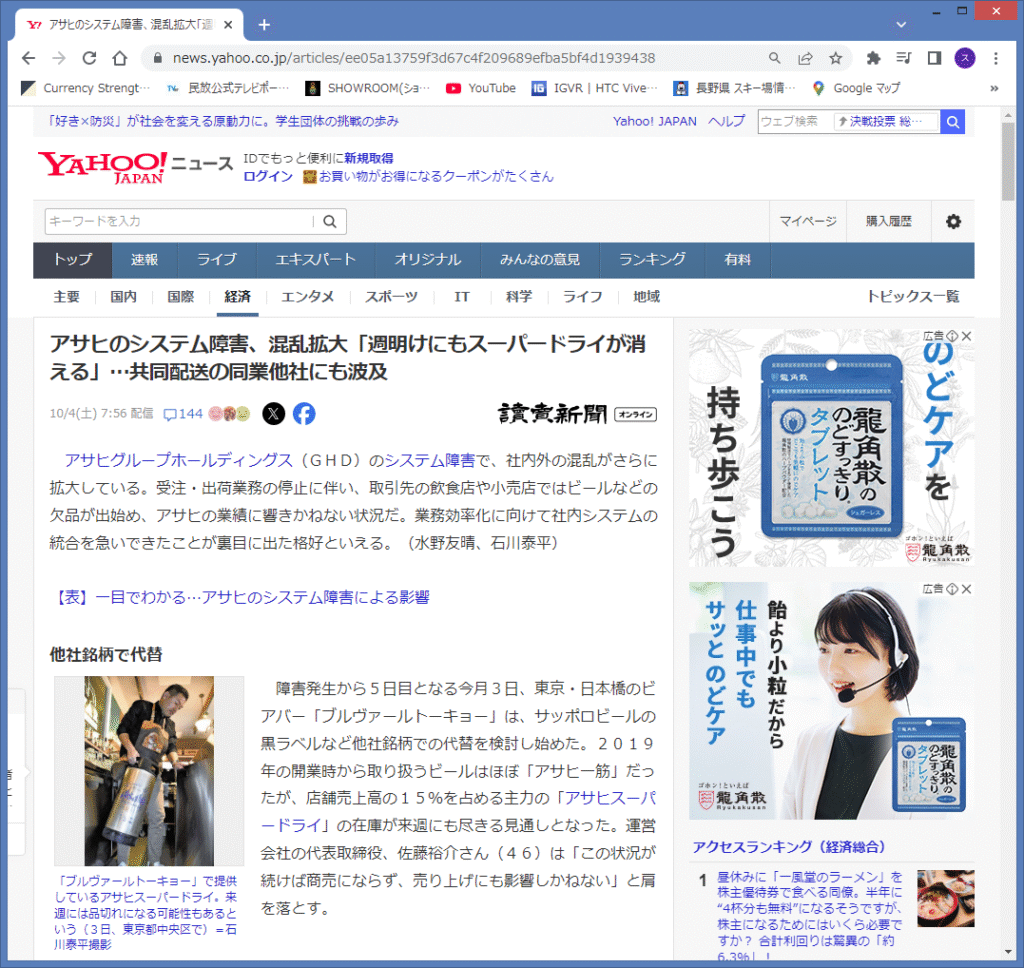
IDLE Shell に、URLの入力と実行した結果を表示します。

ソースで、BeautifulSoupで解析した内容(topics)を、IDLE Shell 上に出力しています。
念の為、内容を記載しておきます。
['現在JavaScriptが無効になっています', 'Yahoo!ニュースのすべての機能を利用するためには、JavaScriptの設定を有効にしてください。JavaScriptの設定を変更する方法はこちら', '10/4(土) 7:56配信', '\u3000アサヒグループホールディングス(GHD)のシステム障害で、社内外の混乱がさらに拡大している。受注・出荷業務の停止に伴い、取引先の飲食店や小売店ではビールなどの欠品が出始め、アサヒの業績に響きかねない状況だ。業務効率化に向けて社内システムの統合を急いできたことが裏目に出た格好といえる。(水野友晴、石川泰平)\n\n【表】一目でわかる…アサヒのシステム障害による影響', '「ブルヴァールトーキョー」で提供しているアサヒスーパードライ。来週には品切れになる可能性もあるという(3日、東京都中央区で)=石川泰平撮影', '\u3000障害発生から5日目となる今月3日、東京・日本橋のビアバー「ブルヴァールトーキョー」は、サッポロビールの黒ラベルなど他社銘柄での代替を検討し始めた。2019年の開業時から取り扱うビールはほぼ「アサヒ一筋」だったが、店舗売上高の15%を占める主力の「アサヒスーパードライ」の在庫が来週にも尽きる見通しとなった。運営会社の代表取締役、佐藤裕介さん(46)は「この状況が続けば商売にならず、売り上げにも影響しかねない」と肩を落とす。', '\u3000影響は同業他社にも波及し、キリンビール、サッポロも一部商品に配送の遅れが出ているという。都内の業務用酒卸売店「佐々木酒店」によると、アサヒを含めたこの3社は都内などで工場や倉庫から問屋に運ぶ際、同じトラックに載せる共同配送を行っており、アサヒの出荷遅延が影響している模様だ。佐々木実社長(70)は「このままでは週明けにもスーパードライの生ビールが消える店が出る」と話す。', '\u3000セブン―イレブンやファミリーマートは、アサヒと共同開発するプライベートブランド(PB)飲料の出荷が止まり、一部店舗は欠品や品薄を周知する貼り紙を掲示し始めた。', '\u3000アサヒはサイバー攻撃を受けた9月29日午前7時頃以降、グループ内で使用するシステムが起動しないなどの不具合が生じた。これによりグループ各社の商品の受注や出荷に加え、コールセンターの顧客対応や、社外からのメール受信もできない状況が続いている。', '\u3000今月1日、飲食店やスーパーからの注文を電話などで受け付ける緊急対応を始め、3日からビールなどを順次納品しているが、正常化にはほど遠い状況だ。システム障害による直接的な影響はないという国内の30工場も、受注や出荷の混乱に伴って多くは生産の一時停止に追い込まれている。', '1/2ページ', '昼休みに「一風堂のラーメン」を株主優待券で食べる同僚。半年に“4杯分も無料”になるそうですが、株主になるためにはいくら必要ですか? 合計利回りは驚異の「約6.3%」!', '元公務員が解説「生活保護はいくらもらえるの?」東京23区・45歳単身世帯の例で試算!受給者が守るべきルール「3つの義務」とは?', '2026年から“独身税”の徴収が始まると聞きました。損をするなら支払いたくないのですが、一体どういうものなのでしょうか?', '持ち家を売却し、老後資金として「1000万円」を得ました。65歳から「家賃10万円」の家で二人暮らしをするつもりですが、持ち家に住んでいた方がよかったですか?', '自民党総裁選後の相場展開を検証!「高市首相」誕生なら相場上昇は継続?', 'Yahoo!ニュース オリジナル', 'Yahoo!ニュースでしか出会えないコンテンツ', '学校で開かれた「説明会」に参加した女子高生、その5年後…月収22万円・新卒1年目23歳になった10月、通帳に記された「残酷な現実」に足がすくんだワケ', '「お母さん、どうしよう。怖い…」…58歳母、震撼。大学2年生・東京でひとり暮らしをする娘から、一通のLINE「衝撃の中身」', '「独り勝ちの快進撃!」ファミマの『コンビニエンスウェア』ラインナップ150種類、ユニクロ並みの価格で高品質\u3000“コンビニで服を買う”時代到来へ', '年金月7万円だが…元会社員71歳おひとり様女性、亡父の遺産700万円を一気に使って「豪華世界一周旅行」。帰国後に待っていた「思い出」の代償【FPが解説】', '仕事を続けながら10億円を築いたテンバガー投資家X氏が「投資で稼いでFIREを夢見る人」に警鐘\u3000「本業の仕事は安易に手放すべきでない」、株式市場は“不確実性の塊”と強調', 'Copyright c 2025 読売新聞社 無断転載を禁じます。']
WordCloud生成(janome)の後、OpenCV でポップアップした画面になります。

ポップアップした画面を閉じると、IDLE Shell 上で、再度、URLの入力を促す内容が
表示されますので、色々なWebページのURLを入力して、WordCloudが生成した
単語(キーワード)を可視化した画像を確認する事が出来ると思います。
Webスクレイピング+WordCloud生成処理(MeCab)
処理概要
- 単語(キーワード)を可視化をしたいWebページのURLを入力
- Requestsブジェクトで、対象のWebページから情報を取得
- BeautifulSoupオブジェクトで、取得した情報を解析
- 解析した内容(トピックス)を、MeCabで品詞や活用型に形態素解析
- 形態素解析した結果を、WordCloudで単語ごとに出現頻度をカウント
- 出現頻度に応じて、サイズを変更して単語を描画して、OpenCVで画像を表示
ソース例:MeCab
次に、Webスクレイピング+WordCloud生成(MeCab)の処理が出来る
ソースを紹介します。
import requests
from bs4 import BeautifulSoup
from wordcloud import WordCloud
import MeCab
from PIL import Image
import numpy as np
from datetime import datetime as dt
import time
import cv2
outfile = './data/scraper_wordcloud.png'
line = "----------------------------------"
# URL情報の取得
def scraping(input_url):
try:
# 指定したWEBサイトから情報を取得
html = requests.get(input_url)
# 取得したHTMLテキストをBeautifulSoupオブジェクトにパース(解析)
parse = BeautifulSoup(html.text,'html.parser')
# 条件に合うすべての要素を取得
parse_tag = parse.find_all("p")
topics = []
for text_data in parse_tag:
topics.append(text_data.getText())
print(line)
print("topics")
print(line)
print(topics)
# Attribute Error(要素が存在していない)例外処理
except AttributeError as e:
print("AttributeError:", e)
return None
return topics
# 解析処理
def purse(input_url):
# 単語の分割
# オプション:辞書は形態素解析器ChaSen用の辞書を採用
tagger = MeCab.Tagger ("-Ochasen")
# URL情報の取得
topics = scraping(input_url)
word_list = []
if topics == None:
print("情報を取得できませんでした")
else:
for word in topics:
# 形態素解析
node = tagger.parseToNode(word)
while node is not None:
# node.feature:品詞(名詞、動詞等)を取得
word_type = node.feature.split(",")[0]
if word_type in ["名詞", "形容詞"]:
# 表層形の取得
word_list.append(node.surface)
node = node.next # 書き忘れると無限ループになるので注意
text = ' '.join(word_list)
# ストップワードを設定
stop_words = [u"あれ", u"これ", u"さん", u"です"]
# Windowsにインストールされているフォントを指定
wordcloud = WordCloud(width=800, height=600, background_color='white',
font_path='./Font/HGRGE.TTC',
stopwords=set(stop_words)).generate(text)
wordcloud.to_file(outfile)
try:
while True:
url = input("Enter URL = ")
url_leng =len(url)
if url_leng == 0:
print("URLを指定して下さい!!")
print(line)
else:
# 開始時間
start_time = time.time()
print(line)
print("処理開始日時:", dt.now().strftime('%Y/%m/%d %H:%M:%S'))
# 解析処理
purse(url)
# 終了時間
end_time = time.time()
# 差分
dif_time = end_time - start_time
# 終了時間
tdatetime = dt.now()
print(line)
print("処理終了日時:", dt.now().strftime('%Y/%m/%d %H:%M:%S'))
print(line)
print("処理時間:", dif_time , "秒")
print(line)
print("WordCloud Make Data Succesfully !!")
print(line)
print("Open scraper_wordcloud_mecab.png !!")
print(line)
img = cv2.imread(outfile)
cv2.imshow("input_url_wordcloud", img)
cv2.waitKey(0)
except Exception as e:
print("Exception: ", e)
except KeyboardInterrupt:
pass
Webスクレイピング処理とWordCloud生成処理の詳細なソース解説は、以前の記事で
紹介していますので、今回は省略します。
上記の処理概要を確認頂ければ、ソースを追えると思います。
ソースの実行例:MeCab
実際に、ソースを起動して、Webスクレイピング+WordCloud生成の処理を実行してみます。
作成したソースの上部のタブメニューより、Run → Run Module を選択するか、
F5キー を押下して、ソースを実行します。
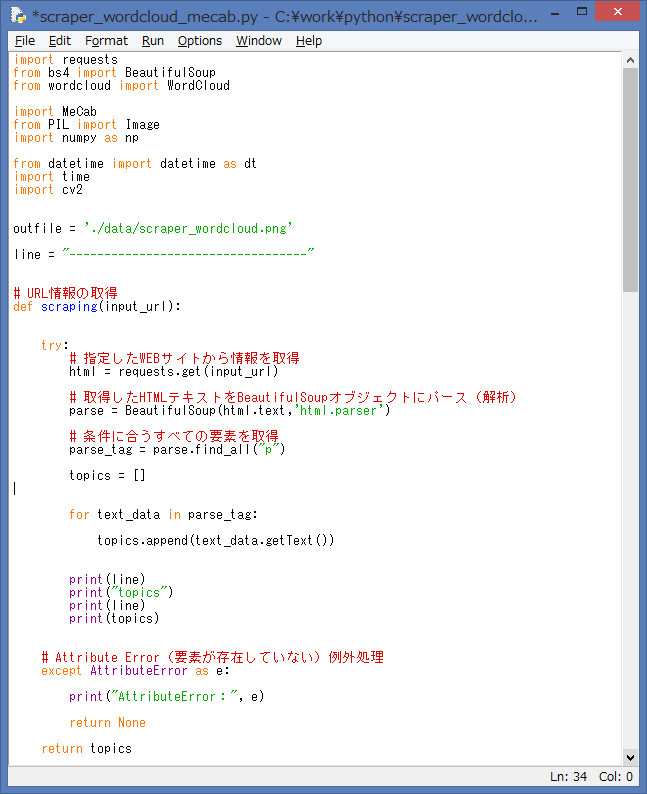
ソースを実行すると、IDLE Shell には、単語(キーワード)を可視化をしたい
WebページのURLの入力を促す内容が表示されます。
では、実際に単語(キーワード)を可視化をするWebページのURLを入力します。
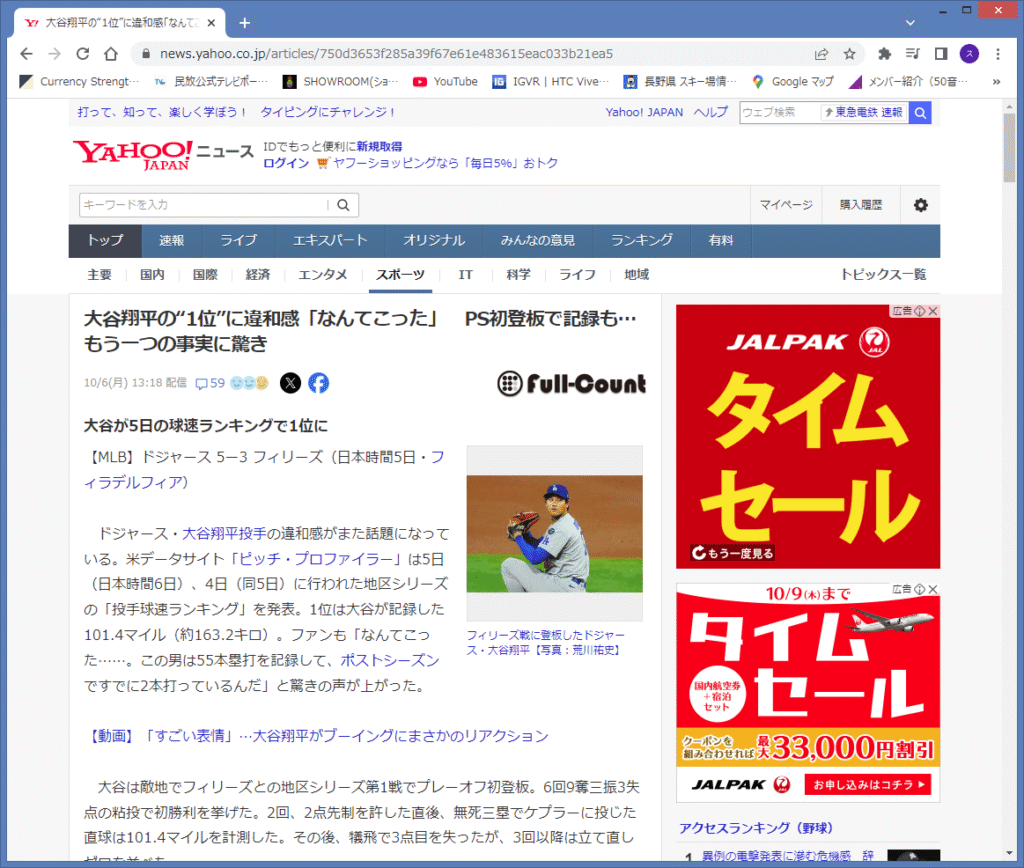
今回は、下記のWebサイトのURLを入力してみます。

この記事を読むタイミングで、対象のWebサイトが存在しない可能性も有りますので、
スクリーンショットを掲載しておきます。
IDLE Shell に、URLの入力と実行した結果を表示します。
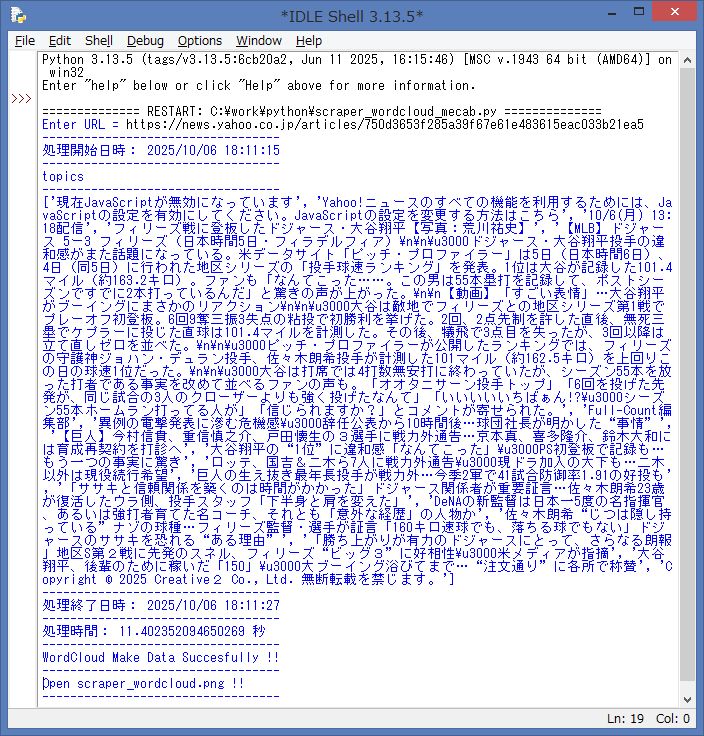
ソースで、BeautifulSoupで解析した内容(topics)を、IDLE Shell 上に出力しています。
念の為、内容を記載しておきます。
['現在JavaScriptが無効になっています', 'Yahoo!ニュースのすべての機能を利用するためには、JavaScriptの設定を有効にしてください。JavaScriptの設定を変更する方法はこちら', '10/6(月) 13:18配信', 'フィリーズ戦に登板したドジャース・大谷翔平【写真:荒川祐史】', '【MLB】ドジャース 5ー3 フィリーズ(日本時間5日・フィラデルフィア)\n\n\u3000ドジャース・大谷翔平投手の違和感がまた話題になっている。米データサイト「ピッチ・プロファイラー」は5日(日本時間6日)、4日(同5日)に行われた地区シリーズの「投手球速ランキング」を発表。1位は大谷が記録した101.4マイル(約163.2キロ)。ファンも「なんてこった……。この男は55本塁打を記録して、ポストシーズンですでに2本打っているんだ」と驚きの声が上がった。\n\n【動画】「すごい表情」…大谷翔平がブーイングにまさかのリアクション\n\n\u3000大谷は敵地でフィリーズとの地区シリーズ第1戦でプレーオフ初登板。6回9奪三振3失点の粘投で初勝利を挙げた。2回、2点先制を許した直後、無死三塁でケプラーに投じた直球は101.4マイルを計測した。その後、犠飛で3点目を失ったが、3回以降は立て直しゼロを並べた。\n\n\u3000ピッチ・プロファイラーが公開したランキングでは、フィリーズの守護神ジョハン・デュラン投手、佐々木朗希投手が計測した101マイル(約162.5キロ)を上回りこの日の球速1位だった。\n\n\u3000大谷は打席では4打数無安打に終わっていたが、シーズン55本を放った打者である事実を改めて並べるファンの声も。「オオタニサーン投手トップ」「6回を投げた先発が、同じ試合の3人のクローザーよりも強く投げたなんて」「いいいいいちばぁん!?\u3000シーズン55本ホームラン打ってる人が」「信じられますか?」とコメントが寄せられた。', 'Full-Count編集部', '異例の電撃発表に滲む危機感\u3000辞任公表から10時間後…球団社長が明かした“事情”', '【巨人】今村信貴、重信慎之介、戸田懐生の3選手に戦力外通告…京本真、喜多隆介、鈴木大和には育成再契約を打診へ', '大谷翔平の“1位”に違和感「なんてこった」\u3000PS初登板で記録も…もう一つの事実に驚き', 'ロッテ、国吉&二木ら7人に戦力外通告\u3000現ドラ加入の大下も…二木以外は現役続行希望', '巨人の生え抜き最年長投手が戦力外…今季2軍で41試合防御率1.91の好投も', '「ササキと信頼関係を築くのは時間がかかった」ドジャース関係者が重要証言…佐々木朗希23歳が復活したウラ側、投手スタッフ「下半身と肩を変えた」', 'DeNAの新監督は日本一5度の名指揮官、あるいは強打者育てた名コーチ、それとも「意外な経歴」の人物か', '佐々木朗希“じつは隠し持っている”ナゾの球種…フィリーズ監督・選手が証言「160キロ速球でも、落ちる球でもない」ドジャースのササキを恐れる“ある理由”', '「勝ち上がりが有力のドジャースにとって、さらなる朗報」地区S第2戦に先発のスネル、フィリーズ“ビッグ3”に好相性\u3000米メディアが指摘', '大谷翔平、後輩のために稼いだ「150」\u3000大ブーイング浴びてまで…“注文通り”に各所で称賛', 'Copyright c 2025 Creative2 Co., Ltd. 無断転載を禁じます。']
WordCloud生成(MeCab)の後、OpenCV でポップアップした画面になります。

ポップアップした画面を閉じると、IDLE Shell 上で、再度、URLの入力を促す内容が
表示されますので、色々なWebページのURLを入力して、WordCloudが生成した
単語(キーワード)を可視化した画像を確認する事が出来ると思います。
まとめ
今回は、Webスクレイピング処理に加えて、以前、紹介したWordCloud生成を組み合わせて、
対象のWebページから、単語(キーワード)の可視化する記事を紹介しました。
Webスクレイピング+WordCloud生成の処理概要を、再度、記載しておきます。
処理概要
- 単語(キーワード)を可視化をしたいWebページのURLを入力
- Requestsブジェクトで、対象のWebページから情報を取得
- BeautifulSoupオブジェクトで、取得した情報を解析
- 解析した内容(トピックス)を、Janome or MeCab で品詞や活用型に形態素解析
- 形態素解析した結果を、WordCloudで単語ごとに出現頻度をカウント
- 出現頻度に応じて、サイズを変更して単語を描画して、OpenCVで画像を表示

次回は、Pythonで、読み込んだテキスト内容を、音声ファイルに出力して、
読み上げる処理を紹介しようと思います。

- イラスト:いらすとや より引用


コメント